Google Cloud で Terraform を導入した話し
こんにちは。オールアバウト SRE 所属 の@s_ishiiと申します。
Terraform Advent Calendar 2021 の 25 日目の記事です。
この記事では Google Cloud で Terraform を導入した話しをご紹介します。
目次
- 導入の経緯
- 導入の流れとその後
- これからの課題
導入の経緯
オールアバウトでは Google Cloud を採用していますが、従来 IaC によるインフラ管理はされておらず手動で構築・運用されていました。比較的大規模なインフラを管理していることもあり、2020 年末の時点でこれ以上手動で管理していくことは不適切との結論に至りました。代表的な理由を以下にいくつかピックアップします。
1. 作業時の安全性
手動でインフラを管理する場合、新たに環境を構築・変更する時は手順書を作ってチームから承認を得て作業に移ります。これは安全な方法に見えるかもしれませんが、実際には作業時の操作ミスや作業者の勘違いで想定外の結果を生む余地があります。Terraform を利用することで事前に作業内容を明確にできるので、作業時の安全性が高まると期待しました
2. SRE メンバーに与えられた強すぎる権限
オールアバウトでは SRE がインフラを一元的に管理していますが、手動管理の都合上 SRE の各メンバーには Google Cloud への幅広い操作権限が与えられていました。これは人為的な事故を誘発するので、IaC の導入とインフラの構築フローを CD 化することによって SRE メンバーの権限を縮小化することが期待されました。
3. 命名規則の強制
サービス種別に応じた命名規則は整備されていましたが、実情として遵守されていませんでした。そもそも新しく SRE に加入したメンバーに命名規則が書かれたドキュメントを共有するフローになっていなかったので、人によっては命名規則そのものの存在を知らないといった事態になっていました。この経験から命名規則を徹底するにはドキュメント整備だけでは不充分で、CI のフローに組み込んで強制させる必要があると考えました。
上記のような理由に加え、当時 GKE クラスタのバージョンアップに伴うインフラ対応が控えていたため、これを期に Terraform を利用しようということになりました。
導入の流れとその後
ここからは Terraform の導入とその後どのように運用にのせていったのかを時系列順に記します。
STEP1. Terraform 導入
オールアバウトには大小 10 以上のサービスがあります。手動構築されたそれらのインフラ群を一度に Terraform のコード化するのは現実的ではないので、ひとまず新しく構築するインフラは Terraform を利用するとしました。
上述の通り、当時のインフラタスクに GKE クラスタの入れ替えがあったため、Terraform で作る最初のリソースとして GKE クラスタが選ばれました。またこれを機にコンテナ内で出力されたログを Cloud Logging のログルータ機能を使って GCS に保存することになったので、ログルータ周りのリソースも Terraform で構築することになりました。
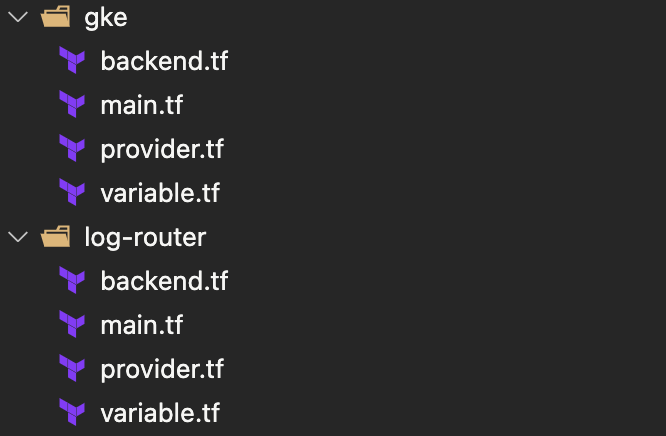
Terraform のディレクトリ構造
この時点では以下のように Google Cloud のリソース単位でディレクトリを分割して state ファイルを作成していました。しかし後になってこの設計は適切でないとの結論に至り、リファクタリングによって変更されることになります。
STEP2. リファクタリング
Terraform を導入して数ヶ月が経過すると、当初の Terraform 設計の問題点が露見してきました。なかでも以下 2 点が問題視され、改善することが望まれました。
- Google Cloud のリソース単位で state ファイルを分割している
- ステージング/本番環境のコードが分離されている
1. Google Cloud のリソース単位で state ファイルを分割している
当初は Google Cloud のリソースを state ファイルの分割単位としていました。単位として充分に小さく、かつ分割単位として明確という理由からこの方針が採用されましたが、実際に運用していくとリソース間参照がしづらくコードを書くうえで苦労しました。
Terraform で異なる state ファイルに記述されたリソースを参照するためには、参照元に output のコードを追記し、参照先でterraform_remote_stateブロックを用いて output されたリソースを取得する必要があります。これはコードの冗長化をもたらし、可読性と生産性を悪化させました。
https://beyondjapan.com/blog/2019/01/reference-other-tfstate-resource/
また当初メリットだと考えていた小さな state ファイル、という点も実際にはあまり恩恵を感じられず、むしろ 1 つのプロジェクト内に state ファイルが分散することにより、コードの更新内容を実環境に適用し忘れる事態が発生していました。
これらの点を踏まえ、state ファイルの分割単位を Google Cloud リソースから Google Cloud プロジェクトに変更しました。state ファイルの単位として大幅に粒度を拡大することになるので、チーム内で「もう少し小さな単位を模索したほうが良いのでは?」という意見も出ましたが、プロジェクトよりも小さい適切な単位を決めるのが難しかったこともあり、プロジェクト単位で state ファイルを分割することになりました。
2. ステージング/本番環境のコードが分離されている
これは書いてある通りで、当初ステージングと本番環境は別々のコードを書いて構築していました。このため時間経過とともに環境の乖離が発生し始めていたので、ステージングと本番で同一のコードを参照するよう実装を見直すことになりました。
リファクタリング後
以上の点を踏まえてリファクタリングした結果、以下のようなディレクトリ構造になりました。
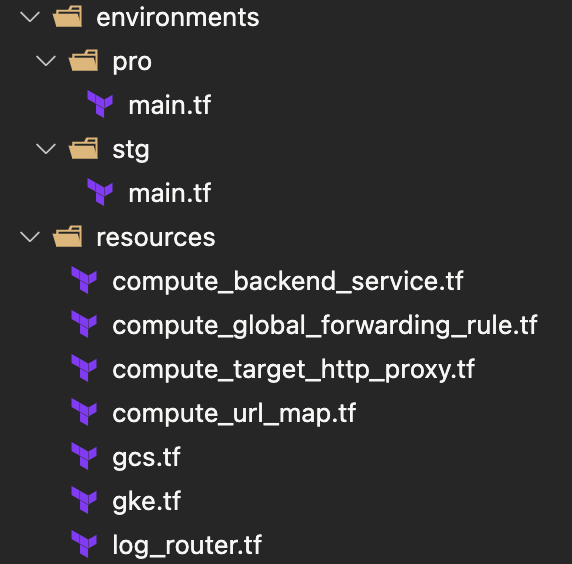
Google Cloud のプロジェクト毎にディレクトリを作成し、その配下に environments、resources ディレクトリを配置しています 。以下が main.tf の記述例です。resources 配下を module として呼び出しており、その際に可変値を埋め込んでいます。このように書くことで resources ディレクトリ配下にコードされた内容をステージング/本番で参照することになり、乖離が起きにくい実装になっています。
terraform { backend "gcs" { bucket = "BUCKET_NAME" prefix = "PROJECT_NAME/stg" } required_version = ">= 0.13" required_providers { google = { source = "hashicorp/google" version = "~> 3.53" } google-beta = { source = "hashicorp/google-beta" version = "~> 3.53" } } } module "stg" { source = "../../resources" region = "asia-east1" project_id = "PROJECT_NAME" env = "stg" }
STEP3. 手動構築したリソースの Terraform 化
ここまでで運用に耐えうる設計になったので(最低限ですが)、いよいよこれまで手動で構築してきたリソース群を Terraform 化することになりました。Terraform 化を進めるに当たって、以下 2 つの方針を前提に進めました。
コードは汚くて良い
Google Cloud で Terraform 化を進める場合terraformerが便利ですが、terraformer で自動出力されたコードの可読性は低いです。これを逐一リファクタリングしていくと相当な時間が消費されてしまうので、Terraform 化の作業のなかではリファクタリングは行わないことにしました。
全てのリソースを網羅しようとしない
オールアバウトがこれまでに構築してきたリソースは膨大なので、漏れなく Terraform 化しようとすると確認含め相当な時間を要してしまいます。目的は既存インフラを更新する際に手動ではなく Terraform で実行できるようにすることなので、更新頻度の低いリソースを頑張って Terraform 化する動機はありませんでした。そのため細部にはこだわず、Terraform 化対応で漏れたリソースは発見次第都度対応していくことにしました。
これらの前提のもと作業した結果、1 ヶ月程度で全環境を一通り Terraform 化できました。 しかしその一方で以下課題も残りました。
コードの可読性が低すぎる
リファクタリングしない前提で進めた結果、リソースの数が多いプロジェクトの可読性が相当低いものになってしまいました。今から考えるとその辺りはもう少し柔軟に対応しても良かったと思っています。
表記ゆれが目立つようになった
これは Terraform 化したおかげで気づけた点でもありますが、命名規則が徹底されていないせいで同じ種類のリソースで微妙に異なる名称が散見されました。これは for_each 等でループする際の障害になるので、将来のいずれかの時点で解消する必要が出てきました。
この 2 つの課題のうち、「コードの可読性が低すぎる」に対処するため週次でリファクタリング会を設け、チームメンバー全員で可読性の低い箇所を探してはリファクタリングしていくようサイクル化しました。
STEP4. impersonate 対応
当初の予定ではこの辺で Terraform の CD 化対応を進める予定だったのですが、他タスクとの優先度の兼ね合いに加え、全ての環境を 1 つの Terraform リポジトリにまとめているモノリポ構成であるため CD の工程が複雑になる等の理由で、CD 化は見送ることになりました。このため当面の間、Terraform は SRE メンバーのローカル端末で実行される状態が続くことになりました。
このような状況のなかで、かねてからの課題であった SRE に与えられた強すぎる権限を解消するために、Google Cloud の impersonate 機能を導入しました。これは事前に許可したサービスアカウントに成り代わることのできる機能で、この機能を Terraform のコードに導入してやると Google Cloud のコンソール画面からはリソース変更等の操作はできず、Terraform を経由した場合にのみ変更が可能になる、といったことが実現できるようになります。
https://cloud.google.com/iam/docs/impersonating-service-accounts
詳しいやり方は以下の記事で分かりやすく紹介されているので、興味のある方はご覧ください。
これからの課題
以上で Terraform を運用していく基礎はできたと考えています。一方で運用の容易性や優秀性を追求する余地もまだ多く残されています。具体的には以下のような課題があり、今後アプローチしていく予定です。
- terraformer で出力したコードのリファクタリング
- CI/CD の導入
- terraform-validator の導入
以上「Google Cloud で Terraform を導入した話し」でした。