20年以上運営してるメディアと周辺サービスの再設計・再構築してるから話を聞いてほしい
こんにちは!株式会社オールアバウト開発部 All Aboutリアーキテクティングプロジェクト PM(言い出しっぺ)兼エンジニアの @C058です。
2022年のアドベントカレンダーも最終日となりました。 これまでのオールアバウトのカレンダーはこちら:
All About Group(株式会社オールアバウト)のカレンダー | Advent Calendar 2022 - Qiita
最終日の記事は、自称:オールアバウトで一番アツい開発をしている「All About リアーキテクティングプロジェクト」についての立ち上げと、 先が見えない問題にどう立ち向かっているかを表面的に紹介したいと思います。
続きを読むGoogle Cloud でサービス アカウントの権限借用(impersonate)を活用して SRE の権限を縮小させた話
こんにちは。オールアバウト SRE 所属 の@s_ishiiと申します。
Google Cloud にはサービス アカウントの権限借用という機能があります。この機能を活用することで普段の運用をより安全にすることができます。この記事ではオールアバウトが導入・実践しているサービス アカウントの権限借用に関して解説します。
前提
オールアバウトでは SRE が全サービスのインフラを一元的に管理しています。このため SRE は全ての Google Cloud のプロジェクトに対してオーナー権限(roles/owner)を保持していました。 SRE メンバー全員がインフラを自由に変更できてしまうため、普段から Google Cloud のコンソール画面で設定を変更してしまわないよう注意しながら運用する必要がありました。
こうした状況を解決する手段としてサービス アカウントの権限借用の活用を検討し始めました。
サービス アカウントの権限借用とは
サービス アカウントの権限借用とは名前の通り別のサービスアカウントの権限を借用する権限です。これだけだと分かりづらいので例を用いて解説します。
- Google Cloud へのログイン・アカウント
- sre@sample.com
- 閲覧者権限(roles/viewer)
- サービスアカウント
- owner@project-id.iam.gserviceaccount.com
- オーナー権限(roles/owner)
ログイン・アカウント(sre@sample.com)には更新系の権限が付与されていないため、Google Cloud 上で何かしらリソースを作成・変更しようとすると権限エラーになります。
しかしサービスアカウント(owner@project-id.iam.gserviceaccount.com)側でログイン・アカウントに対しサービス アカウントの権限借用を与えている場合、ログイン・アカウントからサービスアカウントに成りすますことができます。
これによってサービスアカウントの権限が利用できるようになり、結果として(参照権限しか持っていない)ログイン・アカウントから Google Cloud のリソースを作成・変更できるようになります。
詳しくは以下公式ドキュメントをご確認ください。
https://cloud.google.com/iam/docs/impersonating-service-accounts?hl=ja
目標
前提でも軽く触れましたがサービス アカウントの権限借用を用いることで以下の実現を目指しました。
- SRE メンバーの権限縮小
- コンソール画面から本番環境を変更できないようにする
- Terraform の実行
- Terraform は各 SRE メンバーの PC から実行しているため Terraform 経由の場合は本番環境の設定を変更できるようにする
- 一時的な権限拡大
- 一時的に権限を強化してコンソール画面から本番環境を変更できるようにする(一例として、障害時に DB をフェイルオーバーしたい等のユースケースが想定されました)
Terraform とサービスアカウントの借用権限
上記で解説したサービスアカウントの借用権限は gcloud コマンドと Terraform で利用できます。オールアバウトでは Google Cloud を Terraform で管理しているため Terraform でサービスアカウントの借用権限を利用しています。
具体的な設定手順は長くなるので割愛しますがこれによって閲覧者権限しか持っていないアカウントからでも Terraform 経由で Google Cloud のリソースを更新できるようになりました。
Terraform におけるサービスアカウントの借用権限の設定手順に関心のある方は以下記事をご覧ください。
https://medium.com/google-cloud/a-hitchhikers-guide-to-gcp-service-account-impersonation-in-terraform-af98853ebd37
一時的な権限拡大
Terraform でサービスアカウントの借用権限を使えるようになったことで運用の大部分が解消されたため、SRE メンバーからオーナー権限を剥奪しました。
しかしいざ閲覧者権限のみになると、当初想定していたよりもコンソール画面から変更作業が多いことに気づきました。Google Cloud は Terraform で管理していると書きましたが、Terraform を導入してから 1 年程度しか経っていないこともあり未だに Terraform 管理されていないリソースもあり、コンソール画面を操作して設定変更する機会は少なくなかったのです。
そこで活用したのが一時的な権限の追加です。Google Cloud IAM では権限を一時的に追加する機能があるのでこれを利用することで必要な権限を短時間だけ与えることにしました。
以下コマンド例です。コマンドを実行した時間から 30 分間指定した権限が追加された状態になります。
gcloud projects add-iam-policy-binding <プロジェクトID> \
--member='group:sre@sample.com' \
--condition="expression=request.time < timestamp(\"$(date '+%Y-%m-%dT%TZ' -u -d '30 minute')\"),title=tmp_$(date '+%Y-%m-%d-%T')" \
--role='<ロール名>' \
--impersonate-service-account=owner@project-id.iam.gserviceaccount.com
ちなみに最後に付与しているオプション--impersonate-service-accountはサービスアカウントの借用権限用のオプションになります。
ログイン・アカウント(sre@sample.com)には IAM を操作する権限は無いのですが、サービスアカウント(owner@project-id.iam.gserviceaccount.com)に成りすますことで IAM を操作できるようにしています。
Slack ボットを使って
上記までの対応で当初目標としていたことは達成できたのですが、「一時的な権限拡大が面倒」という課題が残りました。 コマンド 1 つ実行するだけですが、Google Cloud のロールに習熟している人でないとどのロールを割り当てて良いのか調べるところから始めないといけません。 roles/owner のような強力なロールを割り当てられれば良いのですが、一時的な権限付与では roles/owner を含む基本ロールは付与できないため、毎回ケースに応じて必要なロールを選択する必要があり思いの外時間がかかるのです。
このため新しく入ってきた人も簡単に作業ができるよう Slack 経由で実行できるようにしました。以下 Slack ボットの利用シーンになります。


まとめ
サービス アカウントの権限借用を活用することでインフラ管理者の権限を縮小し、不意の事故を防止することができます。
加えて上記のような対応を併せて行うことで、運用の安全性を享受しつつ利便性を維持することができますのでお試しください。
以上「Google Cloud でサービス アカウントの権限借用(impersonate)を活用して SRE の権限を縮小させた話」でした。
All Aboutの基幹DBのMySQLバージョンを5.7から8.0に上げた話
こんにちは。株式会社オールアバウト エンジニアの@hideです。
私たちのチームでは、2022年3〜6月にかけて、オールアバウトの基幹DB(All Aboutの記事やガイドの情報が格納してあるDB)のMySQLバージョンを5.7から8.0に上げる対応を実施しました。
当記事ではその際の移行手順や実際の作業を通して得た知見をまとめます。
これからシステムのMySQLバージョンを上げたいと思っている方の参考になれば幸いです。
環境情報
弊社の主な環境は以下の通りです。
今回はCloud SQLのMySQLバージョンを5.7から8.0に上げる対応を実施しました。
MySQLバージョンアップの動機について
今回MySQLバージョンアップを行った理由は以下の二つです。
- セキュリティ担保のため
- All Aboutのリアーキテクチャに向けた準備
セキュリティ担保のため
一つ目はセキュリティを担保するためです。
MySQL(Cloud SQL for MySQL)にはサポート期限があり、期限が切れてしまうと新規のバグやエラーの修正が行われなくなってしまいます。
バグやエラーはシステムの脆弱性に繋がる可能性があるため、なるべく早くバージョンアップを実施する必要がありました。
All Aboutのリアーキテクチャに向けた準備
二つ目はAll Aboutのリアーキテクチャに向けた準備です。
私たちのチームでは、現在All Aboutのアプリケーション・インフラ構成を設計レベルから作り直す、リアーキテクチャプロジェクトを進めています。
このプロジェクトは数年単位で行う予定のため、本格的に走り出すとMySQLのバージョンアップに時間を割く余裕が無くなってしまいます。
そのため、プロジェクトが本格的に走り出す前の初期段階で対応しておくことになりました。
移行作業の振り返りと得た学び
次に、移行の流れと得た学びを時系列でまとめていきます。
1. MySQL8の変更点を確認
まず最初に行ったのは、MySQL8での主な変更点を確認することです。
チームで定期的に時間を設けて調査を行い、MySQL8の主な変更点を洗い出しました。
特に参考になった記事は以下の二つです。
一つが公式が出している記事で、もう一つがCybozu様がMySQL8への移行を行った際の記事です。
どちらもMySQL8の変更点を知る上でとても参考になりました。
2. 影響範囲の洗い出し
次に、影響範囲(対象のDBと接続しているアプリ)の洗い出しを行いました。
調査の結果、他部署が管理しているシステムも含めて、合計で8つのアプリと接続していることが分かりました。
3. 各アプリのテストケースを作成
影響範囲の洗い出しが終わった後は、各アプリで動作担保用のテストケースを作成しました。

今回は通常の機能追加のテストケースとは違ってどこでエラーが発生するかが分からなかったため、全ての機能を網羅する必要がありました。
4. ステージング環境で動作テストを実施して問題点の洗い出し+エラーの解消
次に、作成したテストケースを使ってステージング環境で各アプリのテストを実施しました。
ここでは、ステージングのDBを使うのではなく、本番環境のDBのデータをステージング用に一部加工したうえでMySQL8化してテストを実施しました。
なぜなら、移行対象のDBは、本番環境とステージング環境でデータの内容や量がかなり異なっていたからです。
データ量によってクエリの動作が変わる場合もあるため、実際の本番環境に近い状態でテストすることはとても重要でした。(実際、メモリ不足起因のエラーは発生しました)
ステージング環境でテストを実施したことで、MySQL8化により各アプリで発生するエラーの洗い出しをすることができました。
発生した主なエラーは以下の2つです。
- MySQL8で削除されたSQLモードに起因するエラー
- データソート時のメモリ不足に起因するエラー
それぞれの原因と解消方法を紹介します。
MySQL8で削除されたSQLモードに起因するエラー
一つ目は、MySQL8で削除されたSQLモードに起因するエラーです。
Laravelで作られたバッチシステムで以下のエラーが発生しました。
SQLSTATE[42000]: Syntax error or access violation: 1231 Variable 'sql_mode' can't be set to the value of 'NO_AUTO_CREATE_USER'
これは、公式ドキュメントにもある通り、MySQL8からNO_AUTO_CREATE_USERというSQLモードが削除されたために発生するようになったエラーです。
具体的には、LaravelではMySQLのstrictモードのオン・オフを設定できるようになっており、オンの場合は以下のようにSQLモードをセットするのですが、MySQL8からはNO_AUTO_CREATE_USERが削除されたためセットできずにエラーとなっていました。
protected function strictMode()
{
return "set session sql_mode='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'";
}
// /vendor/laravel/framework/src/Illuminate/Database/Connectors/MySqlConnector.php
これについては、Laravelでパッチが出ていたため、Laravelのパッチバージョンを上げることで解消することができました。
パッチバージョンを上げた後は、以下のようにMySQLのバージョンによってSQLモードを変えるため、MySQL8にしてもエラーが発生しなくなっています。
protected function strictMode(PDO $connection)
{
if (version_compare($connection->getAttribute(PDO::ATTR_SERVER_VERSION), '8.0.11') >= 0) {
return "set session sql_mode='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_ENGINE_SUBSTITUTION'";
}
return "set session sql_mode='ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'";
}
データソート時のメモリ不足に起因するエラー
二つ目は、データソート時のメモリ不足に起因するエラーです。
Laravelで作られた管理画面の契約書一覧ページで以下のエラーが発生しました。
SQLSTATE[HY001]: Memory allocation error: 1038 Out of sort memory, consider increasing server sort buffer size
これは、MySQL8からデータのソート方式が変わった(正確にはソートの選択方式が変わった)ことに起因するエラーと考えています。
具体的には、以前はレコードのソートをする際に、特定のカラム(IDなど)でソートをした後にデータを取得していたのですが、MySQL8(正確には8.0.20)からはパフォーマンスの観点から、常に指定したカラムのデータをまず全て取得した上でメモリ上で一括でソートするようになりました。
そのため、ソート時のデータ量が増加してしまい、sort buffer sizeが同じ値でもメモリ不足によりエラーが発生したと考えられます。
参考1:ORDER BY の最適化
参考2:MySQLのソート処理について
このエラーの対応方針としては、エラーメッセージにある通り素直にsort buffer sizeを上げても良かったのですが(実際、sort buffer sizeを上げてエラーが解消されることは確認しました)、DB全体のメモリ消費量の増加に繋がる可能性がありました。
そのため今回はクエリチューニングで対応しました。
具体的には、クラスタインデックス(主キーインデックス)を効かせるようクエリを変更することで、データ取得時にソート処理が発生しない(ソート時にメモリが消費されない)ようにしました。
今回紹介した二つのエラーはあくまで弊社の事例であり、他社のシステムで発生するとは限りません。
どういったエラーが発生するかは(ある程度の予測はできるかもしれませんが)断定はできないので、結局は「徹底的にテストをして問題点を洗い出す」がバージョンアップの際の原則なのかなと感じています。
5. データ移行方法の検討と決定
ステージングでの動作検証と並行して、データの移行方法(MySQLのバージョンアップ方法)の調査と検証も行っていました。
調査により、Cloud SQLでMySQLのバージョンを上げる方法としては主に以下の二つがあることが分かりました。
- Database Migration Service(DMS)を使用する方法
- 現在のCloud SQLインスタンスのコンソールからデータをExportし、新しいMySQLバージョンのインスタンスにImportする方法
※Database Migration Service(DMS)とは、別の環境からCloud SQLにデータベースを移行するためのGCPのサービスです。ここでの「別の環境」とは、AWS・Azure・オンプレ等のGCP以外の環境だけでなく、別バージョンのCloud SQLインスタンスからの移行も含んでいます。DMSの概要についてはこちらの動画も参考になるでしょう
これらの二つの方法について動作検証をしつつ比較を行い、結論としてはDMSを用いて移行することになりました。
主な理由は以下の3つです。
- 移行にかかる時間がDMSの方が短い
- 移行当日の作業量がDMSの方が少ない
- DMSではトリガー等の設定が移行される
移行にかかる時間がDMSの方が短い
2通りの方法で移行を試した結果、DMSを用いた場合は1時間半程度でデータのExportからImportまでが完了しました。
しかし、DMSを使わない場合はExportからImportまで8時間以上かかりました。(特にImportに時間がかかった)
当たり前の話としてサービスのダウンタイムは短ければ短いほど良いため、この時点でDMSを使うことはほぼ確定しました。
移行当日の作業量がDMSの方が少ない
他の理由としては、移行当日の作業量がDMSの方が圧倒的に少ないことも挙げられます。
DMSの場合は、事前に「移行ジョブ」を作成しておけば、当日は「移行開始ボタン」を押すだけで移行ができます。
しかしDMSを使わない場合は、Export,Importを手動で行う必要があるのに加えて、後述するトリガー等の設定も全て手動で移行する必要がありました。
当日の作業量が増えると思わぬエラーやミスで時間が延びる可能性もあるため、このDMSの作業量の少なさは大きな魅力の一つと考えました。
DMSではトリガー等の設定が移行される
検証の結果、DMSを用いた場合はトリガーの設定も含めて移行されますが、DMSを使わない場合はトリガーの設定は移行されないことが分かりました。
前述したように、当日の作業量はなるべく減らしたかったため、トリガー等の設定を自動で移行できるDMSの方が有効と考えました。
ちなみに、DMSで移行が保証されているものはこちらの記事にまとめられてあります。
ストアドプロシージャ、ビュー、外部キー制約等は漏れなく移行されます。
ただ、一部DMSでは移行されない設定もあったため、次の項目(本番環境でデータ担保のテストを実施)で紹介します。
6. 本番環境でデータ担保のテストを実施
ステージングでのテストの実施により、エラーの特定と解消は行えました。
しかし、あくまで「マスキングしたデータ」を用いてテストをしたため、「移行前後でデータが変化していないことの担保」はできていませんでした。
そのため、本番環境でコピーインスタンスを作成してDMSを用いたデータ移行を行い、移行前後で同じSQLを流してデータが変化していないことを確認しました。
このとき、移行前後でデータベースに保存されている時間(記事の作成日時など)が変化していることに気付きました。
これは、DMSではCloud SQLのデータベースフラグの設定は移行されないため、移行後のDBのタイムゾーン設定(default_time_zone)がUTC時間になっていたことが原因でした。
※MySQLのTIMESTAMP型の取得時の値はデータベースのタイムゾーン設定に依存する(DATETIME型は依存しない)
これについては、移行元インスタンスと同一のフラグを移行先にも設定することで解消できました。
7. ステージング環境でリハーサルを実施
データ担保のテストを実施した後は、ステージング環境でハーサルを実施しました。
ここでのポイントは、ステージングテストと同様、本番と同じデータ量のDBを使用したことです。
なぜなら、データ量が違うとDMSの移行時間が大きく変わってしまうため、移行時間の正確な計測が難しくなってしまうからです。
具体的には、データ容量に比例してDMSの移行時間も増えていました。
以下、ストレージ使用量の違うDBでそれぞれDMS移行を試した際にかかった時間の比較です。
- 使用量60GiBのDB
- 1時間半程度
- 使用量20GiBのDB
- 30分程度
このリハーサル結果を基に、本番環境での移行手順の作成と作業時間の見積もりを行いました。
また、影響範囲の大きい作業となるため、早めに広く告知することも意識しました。(オールアバウトの場合社外のガイドにも告知が必要)
8. 本番環境で移行作業を実施
最後に本番環境で移行作業を実施しました。
ここで意識したことは、なるべく最小時間で作業が終わるようリリースの順序を工夫することです。
例えばDMS移行の待ち時間の間に各アプリのDB接続情報の変更やリリース準備を進めておくなど、無駄な時間ができるだけ発生しないよう工夫しました。
結果としては、予定より早く3時間半程度で全ての移行作業を完了することができました。
移行を進めるにあたり意識したこと
移行作業を進めるにあたり意識した事は、まずは「ミスをしない」ことです。
DBの移行は一歩間違うと長時間DB(システム)が停止する可能性もあるため、慎重に行う必要がありました。
具体的には、厚くテストをするのはもちろんのこと、リリースの際にも切り戻し用のプランを用意しておくなど、常に悪い状況を想定して準備を行いました。
また、今回は自チームだけでなく複数のチームが連携して動く必要があったため、動き方の認識を合わせるミーティングを開いたり、都度作業の進捗を確認するなどして全体の作業がスムーズにが進むよう調整することも意識しました。
おわりに
個人的にはMySQLのバージョンアップは初めての経験だったため、最初はどこから手を付けていいかも分かりませんでした。
しかし、周りの手を借りたり個人的に勉強しつつ進めることで、何とか大きなミスなく移行作業を終えることができました。
また、同時にDMSやクエリチューニングなどDB周りの知見も多く増やすことができました。
今後は今回の作業で得た知見を日々の業務に活かすのはもちろんのこと、よりDB周りの知見を増やしていけるよう日々精進していきたいと考えています。
最後まで読んで頂きありがとうございました。
All Aboutリビルド:エンジニア募集のお知らせ
オールアバウトでは、2001年にサービスをスタートしたメディアAll Aboutのリビルドに取り組むエンジニアを募集しています。
オールアバウトとしてこれまでメインでは使ってこなかったTypeScriptの採用等、技術的に大きな取り組みにチャレンジできるプロジェクトです。
興味のある方は以下のリンクからお申し込みください。
https://hrmos.co/pages/allaboutgroup/jobs/engineer_rebuild
沢山のご応募をお待ちしております!
開発部で1年間やったこと
 毎年恒例オールアバウトグループの新卒1年目エンジニアが投稿する企画「テックブログ新卒週間2022」を開催します。 今回は、オールアバウトマーケティング開発部の@woodyがお送りします。
毎年恒例オールアバウトグループの新卒1年目エンジニアが投稿する企画「テックブログ新卒週間2022」を開催します。 今回は、オールアバウトマーケティング開発部の@woodyがお送りします。
1.はじめに
2022年4月に入社し、7月まで研修を受けたあと、開発部のマーケティング開発グループのチームに所属して業務を行っています。
本記事では実際にどんな風に業務を行ってきて、どんなことを感じたのかを書いています。
学生時代は統計学を扱う研究室に入っていてアプリ開発よりもデータ分析をメインでやっておりました。
分析だけでなく実際のプロダクトを作れるようになりたいと感じ、事業系会社のアプリ開発会社に就職しました。
初めてのことが多く学びが多かった一年となりました。
2.どんな業務をしているか
2.1.主な開発内容について
現在はコンテンツマーケティングプラットフォーム「PrimeAd」の中のビジネスマッチングプラットフォームの開発業務に従事しています。
広告を出したい広告代理店と広告を載せるメディアをつなぐプラットフォームです。
ビジネスマッチングプラットフォームは新規事業としてはじまり、2020年7月にローンチされたばかりで、現在も試行錯誤しながら事業拡大を図っています。
2.2.使用技術
基本的に以下の技術を使って開発を進めています。
- Kubernetes, Docker
- GCP
- PHP, JavaScript
- Laravel
- MySQL
- CircleCI, Bitbucket, Slack, Trello
3.業務の流れ
チームではアジャイル開発を採用していて2週間単位のスプリントで開発をしています。
私達のチームでは以下の流れで開発を進めています。
- 事業の課題をtrelloに記載し重要度を割り振る
- 重要度の高いものから、開発対象としてタスク化する
- スプリント内で解決すべきタスクを各レーンへ割り振る
- 設計 (ここからペアプロ)
- 実装
- レビュー
- ステージングリリース
- 本番リリース

3.1.事業の課題をtrelloに記載し重要度を割り振る
チームとして事業の課題や開発タスクはTrelloのカンバンで管理しています。
ユーザーからヒアリングした課題や開発中に感じた課題がTrelloのカンバンボードに記載されていきます。
記載されているタスクをもとに重要度を割り振っていきます。
3.2.重要度の高いものから、開発対象としてタスク化する
重要度を割り振ったものの中でどのように開発を進めていくか議論をして、タスクとして進められるようにしていきます。
3.3.スプリント内で解決すべきタスクを各レーンへ割り振る
チームでは二人一組でペアを作って作業を進めています。各レーンに対して合計稼働可能時間を超えないようにタスクを割り振っていきます。
3.4.設計
担当を割り振ったら、設計を行います。 ここからペアで作業をしていきます。
機能の要件や画面設計をしていきます。
3.5.実装
開発するときはペアプログラミングを行っていて、二人一組で交代で意見を出しながら実装をしています。
3.6.レビュー
実装したものをチームでコードレビューをしています。コードレビューを挟むことでコードの品質を担保しています。
3.7.ステージングリリース
コードレビューを経て問題がなさそうであればステージングリリースまで行います。
ステージングとは本番環境と同様の状態でシステムの動作や不具合のチェックを行う段階です。
3.8.本番リリース
ステージング環境で問題がなさそうであればリリースを行います。
4.感じたこと
技術的な学びはもちろんありましたが考え方の学びが多かった一年だなと思います。大きく分けて3つの学びがありました。
4.1.開発においてはデバッグできるかが大事
デバッグとはバグと呼ばれるプログラム上の間違いを見つけて排除する作業のことです。
今まではどのようにコーディングするかが大事だと考えていました。しかしながら実際に開発をしていくと多くの時間をエラーの対応に使うことになりました。
人為的なミスや、想定していないパターンでのエラーはよく出てきます。なのでいかにデバッグを効率よくするかが大事です。
その時に特に「エラー文を出す」「問題を切り分ける」「質問する」ことの3点が大事だったなと感じました。
4.1.1.エラー文を出す
プログラムを書いていく中で、エラーが発生した時にエラー箇所とどんなエラー内容だったかを出力してあげるようにすることでバグの場所の特定が容易になります。
4.1.2.問題を切り分ける
エラーが出たとしてもどこが悪いのか見当がつかない時があったりします。その時は条件を固定したり、検証範囲を狭めたりして問題となりそうな部分をあぶりだすことが有効だったりします。
4.1.3.質問する
どうしてもわからなくなったときには質問して教えてもらったりすることが大事になってきます。
先輩エンジニアに質問をすることで自分が持っていない視点があったりするのですんなりと解決することがあったりしました。
4.2.手運用でカバーすることも候補の一つ
顧客課題を解決するために機能を作っていきますが、やっていくうちにあれもこれもあったらいいとなって実装したい機能が多くなってしまいます。
時間と開発者は有限なので最小限の機能を考え、機能をリリースして顧客のフィードバックを元に改善していくことが大事です。
例えば本来システム化するところを人力で行って、利用されるかを試したりするなどの方法があったりします。
いかに素早く検証ができるかが大事だと身にしみて感じた一年でした。
4.3.どうやるかよりも取り組むべき課題の見極めが大事
どう実装するかも大事ですが、それよりも何を実装するかの方がとても重要です。実装したとしても使われなかったら意味がないので努力が水の泡となってしまいます。
そういった背景から実装している時間と同じぐらいチームでは課題に対する議論を行い、何を実装するかを検討しています。
また課題をいかに解像度を高めれるかが実装までスムーズに行えるかの分岐点となります。何を解決したいのか実際曖昧なまま進めてリリースできなかった機能があったりしたので気をつけたいところです。
5.おわりに
一年を通して開発エンジニアとして実装する力も大事ですが、取り組む上での姿勢やチームとしてどう動いていくかが重要だと感じました。
これからエンジニアとして業務に入る人の参考になれば幸いです!!
最後に、現在オールアバウトでは、エンジニアを絶賛募集中です。
ちょっと話を聞いてみたいなどでももちろん大丈夫です!
少しでも興味を持っていただけた方はぜひ採用サイトからご連絡ください。
CircleCi で OIDC(OpenID Connect) がサポートされたので Google Cloud で試してみた
こんにちは。オールアバウト SRE 所属 の@s_ishiiと申します。
先日 CircleCi で OIDC(OpenID Connect)がサポートされました。
Github Actions で OIDC がサポートされてからこの日が来るのを待ち望んでいたので早速オールアバウトの CI で利用してみました。
https://twitter.com/CircleCIJapan/status/1507524861396422657?cxt=HHwWgsDU2fn35uspAAAA
OIDC があると何が良いのか?
「そもそも OIDC って何が良いの?」という方のために OIDC 登場以前と以後の世界について簡単にご説明します。
従来 Google Cloud 等のクラウドの API やリソース に CircleCi からアクセスするには、クラウド側でサービスアカウントキーを発行し、CircleCi の環境変数として登録する必要がありました。
この方法の問題点はサービスアカウントキーが本質的にセキュアでないという点です。
サービスアカウントキーは明示的に削除しない限り最長 10 年間認証可能なのでキーの漏洩リスクが常に存在します。
OIDC を利用することでサービスアカウントキーなしで認証を通すことができるためよりセキュアな運用が可能になります。
OIDC に関する説明は Github の以下ページでよくまとめられているので関心のある方は一読されることをおすすめします。 https://docs.github.com/en/actions/deployment/security-hardening-your-deployments/about-security-hardening-with-openid-connect
※Understanding the OIDC token 以降は Github Actions 固有の話しです
Google Cloud で CircleCi OIDC を利用する手順
ここからは具体的な設定手順について解説していきます。
Google Cloud で CircleCi OIDC を利用するには以下 2 点が必要になります。
Workload Identity Pool の作成(Google Cloud)
基本的な手順は Github の以下ページで詳細に説明されています。 https://github.com/google-github-actions/auth#setting-up-workload-identity-federation
オールアバウトでは Google Cloud のインフラ群は Terraform で管理しているので以下のようなコードで設定しました。
locals { circleci_organization_id = "<CircleCi Organization ID>" } resource "google_iam_workload_identity_pool" "circleci" { provider = google-beta workload_identity_pool_id = "circleci-pool" } resource "google_iam_workload_identity_pool_provider" "circleci" { provider = google-beta workload_identity_pool_id = google_iam_workload_identity_pool.circleci.workload_identity_pool_id workload_identity_pool_provider_id = "circleci-prvdr" attribute_mapping = { "google.subject" = "assertion.sub" "attribute.actor" = "assertion.actor" "attribute.repository" = "assertion.repository" } oidc { allowed_audiences = [local.circleci_organization_id] issuer_uri = "https://oidc.circleci.com/org/${local.circleci_organization_id}" } } module "circleci_sa" { source = "terraform-google-modules/service-accounts/google" version = "~> 4.1.1" display_name = "CircleCi Service Account" project_id = var.project_id prefix = "sa-${var.env_code}" names = ["circleci"] project_roles = [ "${var.project_id}=>roles/artifactregistry.writer", ] } resource "google_service_account_iam_member" "circleci_sa" { service_account_id = module.circleci_sa.service_accounts[0].id role = "roles/iam.workloadIdentityUser" member = "principalSet://iam.googleapis.com/${google_iam_workload_identity_pool.circleci.name}/*" }
やっていることをまとめると以下 3 点になります。
- Workload Identity Pool の作成
- Workload Identity Provider の作成
- ID 連携用のサービスアカウントの作成
基本的には 上記で紹介した Github のページで説明されていることを Terraform で書いただけですが、audience として CircleCi のOrganization IDを追加で設定しています。
何故 audience の設定を追加しているのかというと、Github Actions と CircleCi で発行する OIDC Token の中身が違うためです。
具体的には CircleCi の OIDC Token には aud 値として CircleCi の Organization ID が入るため Workload Identity Provider 側でこの値を許可するよう設定する必要があります。
なお、CircleCi の Organization ID は管理画面の Organization Settings からご確認頂けます。
アクセストークン取得用のコードの追加(CircleCi)
Google Cloud の設定が完了したら次は CircleCi 側のコードを変更します。
CircleCi のドキュメントを読むと今回のリリースで CircleCi の各 Job で CIRCLE_OIDC_TOKEN という環境変数が利用可能になっており、この変数に OIDC Token が格納されています。
https://circleci.com/docs/ja/2.0/openid-connect-tokens/
この OIDC Token を最終的にサービスアカウントのアクセストークンと交換するようコードを書いてやる必要があり、具体的には以下のようなコードになります。
- run:
name: Google Authentication
command: |
ACCESS_TOKEN=`curl -X POST -s \
-H "Content-Type: application/json; charset=utf-8" \
-d "{
"audience": \"//iam.googleapis.com/projects/<< parameters.project_number >>/locations/global/workloadIdentityPools/circleci-pool/providers/circleci-prvdr\",
"grantType": \"urn:ietf:params:oauth:grant-type:token-exchange\",
"requestedTokenType": \"urn:ietf:params:oauth:token-type:access_token\",
"scope": \"https://www.googleapis.com/auth/cloud-platform\",
"subjectTokenType": \"urn:ietf:params:oauth:token-type:jwt\",
"subjectToken": \"${CIRCLE_OIDC_TOKEN}\"
}" \
"https://sts.googleapis.com/v1/token" | jq -r .access_token`
SA_ACCESS_TOKEN=`curl -X POST -s \
-H "Authorization: Bearer $ACCESS_TOKEN" \
-H "Content-Type: application/json; charset=utf-8" \
-d "{
"scope": [
\"https://www.googleapis.com/auth/cloud-platform\"
]
}" \
"https://iamcredentials.googleapis.com/v1/projects/-/serviceAccounts/<< parameters.sa_email >>:generateAccessToken" | jq -r .accessToken`
echo $SA_ACCESS_TOKEN | docker login -u oauth2accesstoken --password-stdin https://asia-east1-docker.pkg.dev
※<< parameters.sa_email >> には Google Cloud 作成したサービスアカウントのメールアドレスが入ります
詳細な説明は Google Cloud の以下公式ページをご確認頂くとして、簡単に説明すると 1 回目のリクエストで Workload Identity の認証を通し、2 回目で事前に設定したサービスアカウトを一時的に借用するためのリクエストを送信しています。
https://cloud.google.com/iam/docs/access-resources-oidc?hl=ja#exchange-token
動作確認
上記コードを動かすと以下のようになります。 (実際にはこの後続の step で Docker イメージを build して Artifact Registry に Push しています)
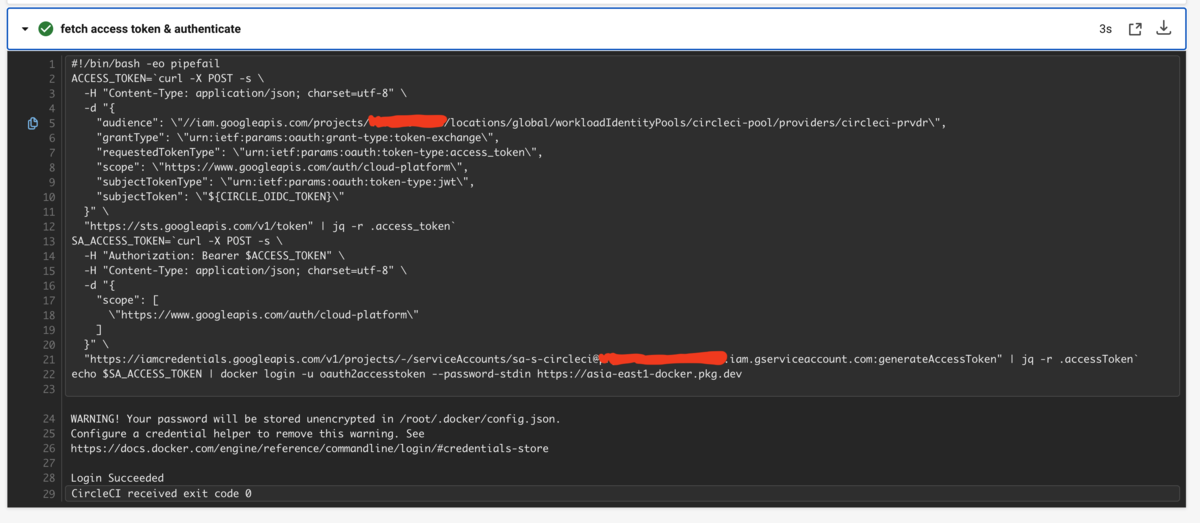
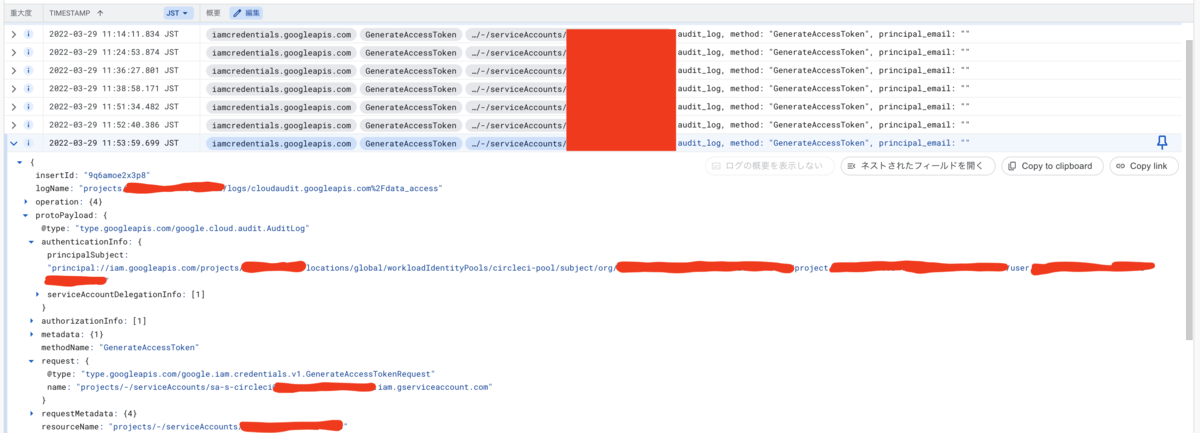
また、Google Cloud 側ではサービスアカウントが借用されたログを確認できます。 (事前に監査ログを有効化する必要があります)
まとめ
CircleCi の OIDC はサポートしたばかりのため Orb がまだ作られておらず、トークン取得周りのコードを自分で書く必要があります。
これはなかなか大変ですが、一度実装してしまえばサービスアカウントキーの管理から開放されるのでメリットは非常に大きいです。
今回は Google Cloud での実装例の紹介でしたが、もちろん AWS 等の他のクラウドでも利用できるので CircleCi を利用されている方は利用を検討することをおすすめします。
以上、「CircleCi で OIDC(OpenID Connect) がサポートされたので Google Cloud で試してみた」でした。