新卒が感じた仕様調整の難しさ

はじめに
オールアバウトグループの新卒1年目エンジニアが投稿する企画『テックブログ新卒週間2022』。
今回はタケウチがお送りします。
私は2021年4月に入社し、7月半ばまでオールアバウトグループ研修とアプリ開発研修を受けました。 研修後には、メディア開発1グループに所属し業務をしています。
本記事ではメディア開発1グループがどのような働き方で、私が実際にどのような業務に取り組んできたのかを紹介します。また振り返りを兼ねてチームで業務を進めるにあたって難しさを感じた他部署、他グループとの仕様の調整について紹介していきます。
どんな業務をしているか
私の所属するグループでは、All About、All About Newsという2つのメディア運営に関するシステムの開発・保守をしています。
具体的なシステムの開発・保守としては以下が挙げられます。
- ユーザーが記事閲覧しやすいようにメディアのデザインや機能の改善
- All Aboutの記事を他社のニュースプラットフォームへ提供・配信する機能の開発
- 記事入稿システムの機能改善(記事入稿の補助機能など)
業務の進め方
業務の進め方としてはスクラムを採用しており、1スプリントの期間は1週間です。この期間で開発を進めています。
※スクラムとは
スプリントは毎週木曜日に始まります。
木曜日にメディアを担当する企画チーム、編集部との定例で開発する機能や施策の優先順位を決めます。それからスプリントプランニングを行い、スプリントで実施する施策を決めます。そしてスプリントでやる内容を企画チーム、記事制作チームに確認してもらい、合意を得ます。
金曜日から水曜日で施策や機能の開発に取り組みます。
そして次のスプリントの初日である木曜日に、前回のスプリントで開発した施策や機能を企画チーム、編集部に向けてデモをしてレビューをしてもらいます。 その後に開発する機能や施策の優先順位を決めるといったサイクルでスプリントを回していきます。
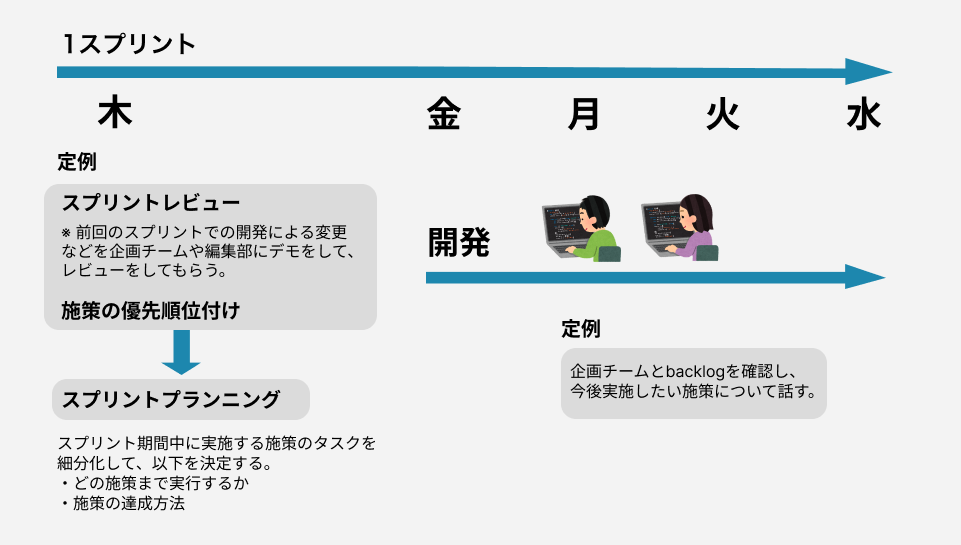
また業務の特性上、エンジニアだけで完結する業務はほとんどなく、企画チームや編集部とコミュニケーションを取りながら仕様や開発のゴールを決めていきます。
その仕様決めのコミュニケーションがうまくいかず、スプリントに遅れが生じ、苦労したケースが何度かあります。次にそこを掘り下げます。
苦労した仕様決め
メディア開発1グループでは、プロジェクト管理ツール「Backlog」を用いてタスクを管理しています。定例ではBacklogを企画チームや編集部と確認し、開発の要件やゴールを記載していきます。
開発を進めていくにあたって新たな考慮点が発生することがあるのでその都度、仕様を決めていきます。
最も仕様決めに時間のかかっていた、メディア開発1グループに所属して数ヶ月間のコミュニケーションを振り返ってみると、簡単なタスクにも関わらず仕様を決めるのに数日かかっていました。また先輩の助け無しでは仕様漏れも現在より頻繁に起こっていました。
チームメンバーからの指摘もあり、以下が課題になっていると考えました。
- 文章を長く書いてしまって読みづらく、相手に意見を伝えるのに時間がかかる
- 仕様をどうするか全て質問してしまっている
1. 文章を長く書いてしまって読みづらく、相手に意見を伝えるのに時間がかかる
文章が読みづらいことが原因でコミュニケーションのラリーが何度も発生していました。そのため自分の時間だけではなく、返信している関係者の時間まで無駄に消費してしまう状態になっていました。
オールアバウトには『ななメンター』という制度があり、新卒に自分の所属するグループ以外の先輩がメンターとしてつきます。そのななメンターでのランチの際に先輩にコミュニケーションの取り方について相談しました。
ななメンターからは文章力についての本(『メール文章力の基本 大切だけど、だれも教えてくれない77のルール』)を紹介してもらいました。
本から得た文章を書く際の以下のテクニックを特に意識するようになりました。
- 文章ではなく箇条書きを原則とする
- 曖昧な表現を使用しない
- 主語、主体を明確にする
- 本文で説明するか、添付ファイルで説明するかを検討する
上記を意識して、社内のslackの文章で改善できる箇所を見つけて修正していくことで、本から得た学びをアウトプットしていきました。
そして、修正した文章をななメンターとのランチ会でレビューをしてもらいました。
また先輩方の文章などを参考にして徐々に改善していきました。
2. 仕様をどうするか全て質問してしまっている
質問相手に仕様を任せていることも同じくコミュニケーションが何度も発生する原因でした。
企画チームや編集部は仕様を全て把握しているわけでは当然ないので、質問されてからどうするかを考える時間が発生します。
また仕様によって開発の工数も変わるので、企画チームや編集部は容易に決めることができません。
例えば、『記事の更新日を記事の上部に表示したい』という施策があったとします。
これまでは以下のように企画チームに質問していました。
PC版の記事更新日の表示位置を変更する施策について質問があります。
具体的に記事のどの箇所に追加したらよろしいでしょうか?
これでは企画チーム側でどの箇所に表示をしたいかを0から考える必要があります。
そのため質問として相手側に丸投げするのではなく、こちらから案を出すように意識的に変えていきました。
PC版の記事更新日の表示位置を変更する施策について相談があります。
記事更新日をどの箇所に表示しましょうか?
記事更新日の表示位置についてPC版のモックを3案作成しました。
スプレッドシートに記載しております。
どの案が良いか、もしくは他の表示位置を検討する必要があるかをご意見いただきたいです。
上記のように相談することで、相談される側もどう返事をするかを考えやすくなりますし、仕様のすり合わせにかかるコミュニケーションの量も以前より減らすことができました。
終わりに
メディア開発1グループに所属した自分がどのように業務をしているのか、苦労した仕様決めのコミュニケーションをどう改善していったのかを紹介しました。
開発が思うように進まなかったり、仕様をなかなか整理できなかったりとうまくいかないことが多い新卒の1年間でした。
しかし、このブログを書くにあたり過去のslackでのコミュニケーションや資料、プルリクエストなどを振り返ると成長していることは感じられました。
今後も開発の力とコミュニケーション力を鍛えて、出来ることを着実に増やし、仕事を楽しく進めていきたいと思います。
オールアバウトエンジニアのSlack人気スタンプを調査してみた
 毎年恒例オールアバウトグループの新卒1年目エンジニアが投稿する企画「テックブログ新卒週間2022」を開催します。
毎年恒例オールアバウトグループの新卒1年目エンジニアが投稿する企画「テックブログ新卒週間2022」を開催します。
今回は、オールアバウトメディア開発部の@eeveeがお送りします。
はじめに
突然ですが、皆さんはSlackをご存知ですか?
株式会社オールアバウトでは、社内のコミュニケーションツールとしてSlackを採用し、業務上のやりとりを行っています。
Slackでは投稿に対して文字で補足や反応する代わりに絵文字でリアクションを取ることができます。
Slack公式の定義にならい、この絵文字でのリアクションのことを絵文字リアクションと呼びます。
社内Slackでは、多種多様なカスタム絵文字が登録され、絵文字リアクションがコミュニケーションの一環として使われています。
社内Slackの絵文字リアクションを集計してみるとチームごとのコミュニケーションの違いが現れておもしろいのではないかと思い、人気絵文字リアクションを調査してみました。
本記事では、その調査方法と結果を紹介したいと思います。 社内Slackのデータを分析してみたい方、またオールアバウトの開発チームのSlack事情気になる!という方の参考になれば幸いです。
自己紹介
私は非情報系学部出身で、業界未経験から新卒入社しており、今回のようなWEB APIを使ったデータ集計は初めての試みでした。 そのためかなりの試行錯誤を経て集計しており、今回ご紹介する実装方針はあくまで一例であるということを前提に読んでいただければと思います。
私は開発部の中でも、オールアバウトで運営するメディアや社内CMSの開発・メンテナンスをするチームに所属しています。 個人作業のときもありますが、基本はペアで開発業務を進めています。
私のチームはエンジニア同士だけではなく、企画グループや社内CMSを利用する記事編集グループなどと部署内外問わず様々なやりとりを行っています。
チーム内での報告・連絡・相談や部署内外でのやりとりでは、「はじめに」で記載したようにSlackを利用しています。
一行で済む返信は絵文字リアクションで伝えて良いこととしたり、問い合わせが来た場合には確認したら絵文字リアクションをとるようにするなど、Slackでのコミュニケーションを重要視しているチームです。
Slackのスタンプを解析してみた
同じ開発部でもチームによって、Slackの使い方の方針は異なるようです。
Slackの絵文字リアクションを集計してみるとチームごとの特徴・働き方の違いが現れておもしろいのではと思い、普段使われている絵文字リアクションのデータを分析してみることにしました。
集計ルール
今回の集計ルールは以下のとおりです。
- 集計項目
- メッセージに対する絵文字リアクションの使用回数
- カスタム絵文字と通常の絵文字どちらも対象とする
- 集計範囲
- タイムラインに載っているメッセージのみ集計範囲とする
- 直近の2000件のメッセージが対象
- メッセージに含まれる絵文字は絵文字リアクションではないため対象外
全体の実装の流れ
今回のようなデータ分析を行うときはPythonを用いることが多いと思いますが、今回は勉強のために業務で用いるPHPで実装を行いました。
実装の流れはざっくり以下のとおりです。
SlackAPIを利用する準備
- Slack Appの作成
- scopeの設定
実装
- Slackからメッセージ履歴とカスタム絵文字データを取得
- 絵文字データを抽出・集計
SlackAPIを利用する準備
SlackAPIとは、他のアプリケーションでのAPIと同様に外部アプリケーションからSlackを操作するための仕組みです。
SlackAPIの中でもWebAPIやEventsAPIなど様々な種類のAPIがありますが、今回はWebAPIを使用します。
公式のドキュメントはこちらです。
必要なSlackAPIが何なのかはこちらが参考になります。
まずはSlack Web APIを利用するための準備をしていきます。
Slack Appを作成する
データ調査を行うためにはまず、SlackAppを作成する必要があります。
そのApp用のトークンを発行し、トークンを用いてApp経由でチャンネルのデータを取得します。
ここは検索してみるとやり方をまとめたQiitaがすぐに出てくるのであまり苦労することはありません。 今回は以下のQiitaを参考に設定しました。
また、作成したSlackAppには使いたいメソッドごとに必要な権限を付与しないとAPIを利用できません。
ここで注意する点があります。
付与する権限はUserとBotで別れており、Appをどのように用いるかで利用する権限が異なります。
botとして権限を付与すると、データを取得したいチャンネルにSlackAppを登録しないとAPIを利用できないようです。
使いたいメソッドのリファレンスに、必要な権限も書いてあるためしっかり確認しておきましょう。
実装の流れ
SlackAPIメソッドを使って、メッセージ履歴とカスタム絵文字を取得します。 これに必要なメソッドはそれぞれ、conversations.historyとemoji.listです。
それぞれのメソッドのリファレンスはこちらです。
メソッドにはそれぞれ必要な権限があるので、使うメソッドを決めたらそのメソッドのRequired scopesを確認してSlackAppに必要な権限を追加しましょう。
メッセージ履歴とリアクションの取得
APIメソッドを使用する際、引数のchannelには、Slackのチャンネルリンクを発行した際にわかるIDを設定します。
今回は特定のチャンネルを指定してそのメッセージ履歴を取得するので、IDを引数にベタ書きしました。
ほかのやり方としては、channels.listというAPIメソッドもあり、publicチャンネルIDの一覧がとってこれるのでそれを使うこともできると思います。
conversations.historyではメッセージそれぞれに対するリアクションとして絵文字名とその回数を取得できます。 ここでemoji.listメソッドを使い、絵文字リアクションをカウントアップしていきます。
絵文字一覧の取得
emoji.listメソッドで取得できるのはカスタム絵文字の登録名と画像のURLの一覧です。 Slackに登録されているデフォルトの絵文字は入っていません。
もしカスタム絵文字以外のデフォルトの絵文字でもカウント対象としたい場合は、どうすればよいのでしょうか。
いろいろなやり方があるとは思いますが、今回は、カスタム絵文字データから絵文字名を抽出し、絵文字名をキー、回数(初期値として0)をバリューにした連想配列にしてカウント用の絵文字リストを作りました。
そして、conversation.historyで取得した絵文字リアクションが絵文字リストに含まれている場合はそのままバリューをカウントアップし、含まれていないデフォルトの絵文字の場合は絵文字リストに追加してキーとバリューを登録するようにしました。
これで全絵文字がカウントできるようになりました。
カウントする際に気をつけるポイント
conversations.historyメソッドではとってこれるメッセージ数のlimitとしてMAX1000件となっています。
引数で取得したいデータの期間を設定できますが、1000件以上になると意図した期間のメッセージをとってこれないので気をつけてください。
また、conversations.historyメソッドではスレッド内のリプライは基本的に取得できません。スレッド内のリプライであってもチャンネルに送信すれば、タイムラインに載るためメッセージとして取得します。
あくまでもチャンネルのタイムラインに投稿されているメッセージだけを取得するメソッドなので気をつけましょう。
もしリプライもとりたい場合は、conversations.repliesというメソッドをさらに使用する必要があります。
とってこれるデータや必要な引数がconversations.historyと少し異なりますので、リファレンスのテスターから試して確認してみてください。以下がリファレンスです。
もう一点気をつけたい点として、SlackのAPIメソッドは定期的にアップデートされるということです。 今回紹介したメソッドが廃止されてほかの名前になっていることもありえます。
例として、conversations.historyメソッドができる前は、channels.historyという名前の別のメソッドだったようです。二次情報の記事の内容は参考程度にして、メソッドが存在するかや必要な権限は自分で確認するようにしましょう。
調査結果
それでは、調査結果を載せていきます。
対象のチャンネルは、以下のとおりです。
- エンジニア同士の連絡用チャンネル
- 私の所属するメディア開発1グループ
- AllAbout IDの開発をおもに手掛けるメディア開発2グループ
- BMP(ビジネスマッチングプラットフォーム)の開発をおもに手掛ける、マーケティング開発グループ
まずはエンジニア同士の連絡用チャンネルの結果です。
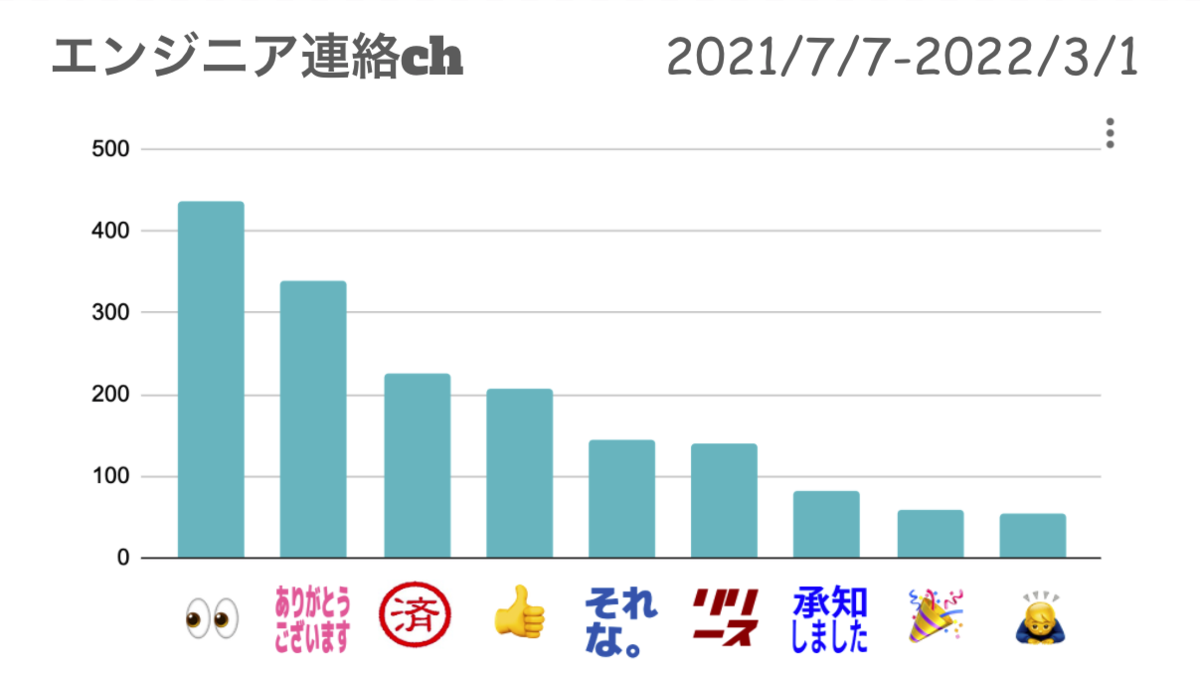
大事な連絡事項が多いチャンネルのためか、『確認中』の意味の目の絵文字リアクションが一位でした。確認済みであることがひと目でわかって便利な絵文字リアクションですよね。
特徴的だったのは、クラッカーの絵文字リアクションがランキングに入っていたことです。
これはリリース完了連絡に対するお祝いやねぎらいの意味合いで使用されているようです。ちょっとした気持ちを伝えられるのも絵文字リアクションのよいところですよね!
また、Slackbotのリマインダー通知に対する『それな。』や『済』の絵文字リアクションがランキングに色濃く反映されていたのはおもしろかったです。
ここからは、開発グループごとの結果を見ていきたいと思います。
私の所属するメディア開発1グループの結果です。
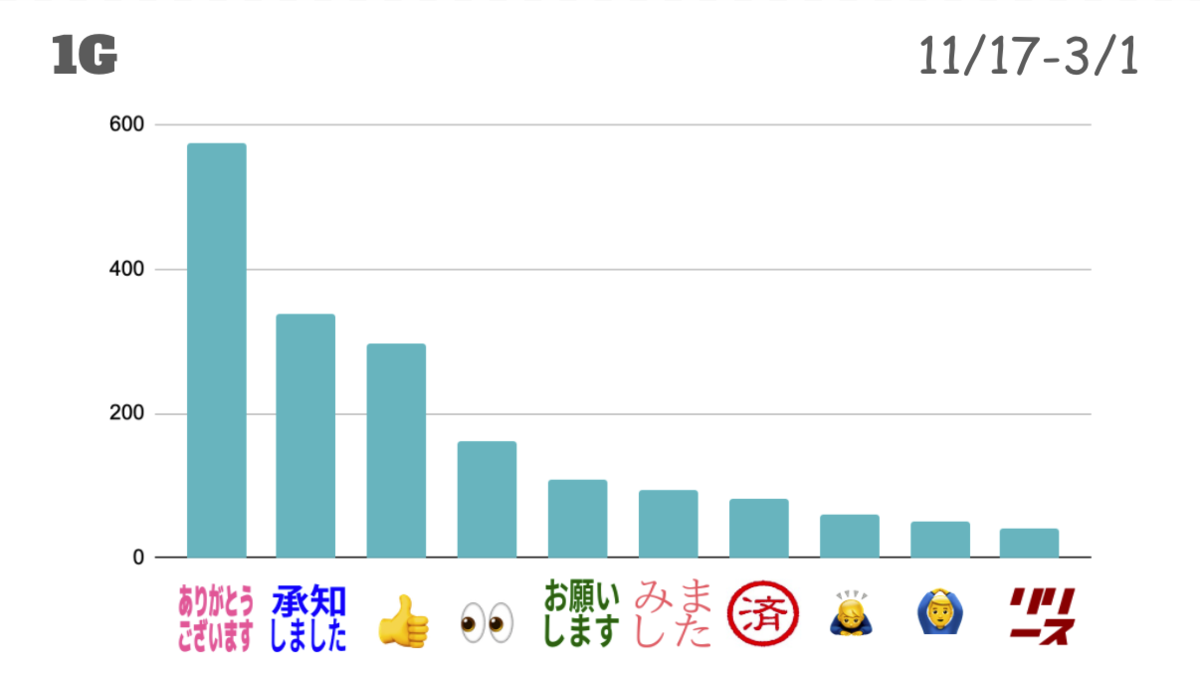
前述の通り、積極的に絵文字リアクションを活用するようにルールとして決めていることもあり、スタンプの総数が多かったです。
『ありがとうございます』や『承知しました』だけでなく、『いいね』や『確認中』の意味の目の絵文字も多く、メッセージに対して絵文字リアクションをとる文化が定着していそうだということがわかりました。 また、自分のメッセージに対して絵文字リアクションをとることで自分の状態を表すといった場合もあるため、人気ランキング10位圏外にも多種多様なカスタム絵文字がありました。
続いて、メディア開発2グループです。
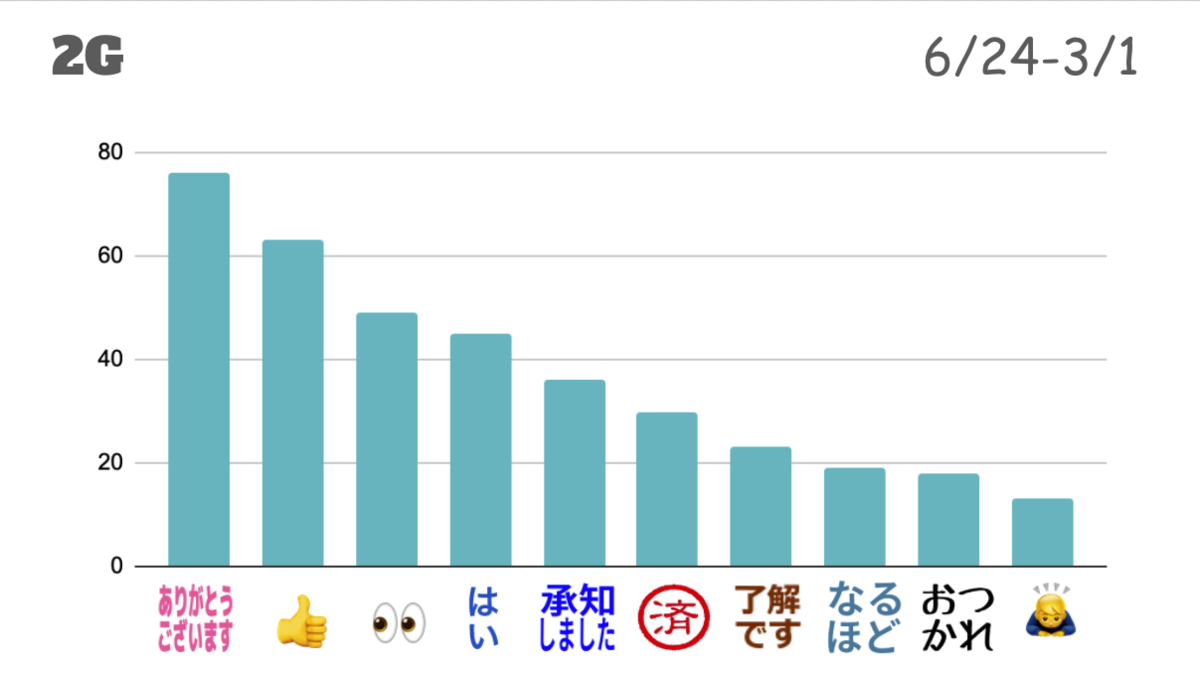
人数が少ないこともあってか、1Gと比べてメッセージ自体も絵文字リアクションの総数も少ないことが印象的でした。
1Gでは報告・連絡・相談は基本的にSlackでやりとりしているのに比べて、2Gでは口頭などのSlack以外のコミュニケーションがメインと考えられます。
Slackでは必要最低限のコミュニケーションをしているように感じました。
人気絵文字リアクションの種類は業務連絡が多いことについては似ていますが、1Gとの違いがわかりますね。
続いて、マーケティング開発グループです。
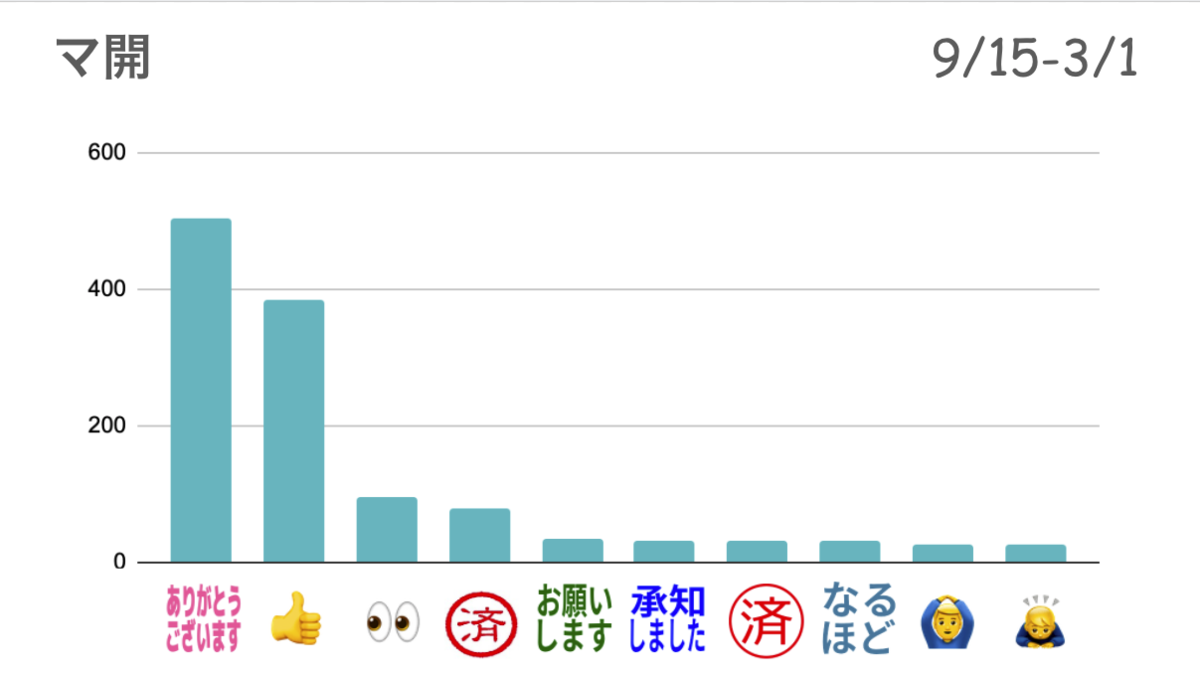
こちらも人気絵文字リアクションの種類はほかと似ていますが、『ありがとうございます』と『いいね』の絵文字リアクションが大半を占めているのが特徴的でした。
メッセージ自体の数は1Gよりは少ないですが2Gよりも多く、Slackでも活発にやりとりされていることがわかりました。
人気ランキング圏外にも、チーム内で感謝を伝えるときに用いるカスタム絵文字があったりしておもしろかったです。
最後に
今回は社内Slackで使われている人気絵文字を調査してみました!
グループごとに雰囲気や働き方の違いがかなり現れていて、おもしろかったです。
また、APIを使って個人的にデータを分析してみたり集計してみたりといったことは初めて行ったので、よい勉強の機会になったと感じました。
試行錯誤する中で妥協した点至らなかった点もあり、現時点での自分の力を図ることもできてよかったです。
新卒一年目を卒業するということで、これからはインプットだけではなく今回のようなアウトプットの機会も積極的に設けていければと思います。
開発部で1年間働いてみて学んだこと 〜想像よりも幅広かったエンジニアの仕事〜

毎年恒例オールアバウトグループの新卒1年目エンジニアが投稿する企画「テックブログ新卒週間2022」を開催します。
今回は、オールアバウト開発部の@barmがお送りします。
1. はじめに
今年の4月でオールアバウトに入社してから1年が経ちます。 研修を終えた後、All Aboutの会員基盤であるAll About IDの構築に参加し、会員専用ページにデザインを適用したり、既存のサービスから会員専用ページへの導線を追加する実装を主に担当していました。 現在は構築した会員基盤をもとにしたサービスの開発を進めています。
今回の記事では、これらの業務をやってきた中で学んだことを、入社直後に思っていたことと比較して紹介していきたいと思います。
2. 学んだこと
コードを書くことだけが開発じゃない
入社した当初、指示通りのものを作ることがエンジニアの仕事だと想像していました。 実際にそういうこともありましたが、エンジニア側でもどういうものを作ればいいのか、ユーザーが使ったときにどう思うのかを考えながら開発を進めていくことが多かったです。 例えば以下のようなことは話し合われていました。
- アンケートの入力フォームの送信・修正ボタンの配置はどうあるべきか
- アンケートに回答し終わったらユーザーはどの画面に戻りたいか
- マイページなのか、All Aboutのトップページなのか
- エラーが起きたとき、ユーザーにどう動いて欲しいのか
- 例えば、同じウェビナーに2回申し込みをされたときに「申し込み済みです」と画面に出すか、エラーページに遷移させるか
ただ指示されたものをコードに書き起こすだけでなくて、どう出来上がると嬉しいかを考えることも開発の一部ということを学びました。
レビューをもらうことの重要さ
自分が書いたコードをチームのメンバーにレビューしてもらうことにはメリットが多いです。 最初は、コードをレビューすることの主な目的はミスがないかのチェックだと思っていました。 ですが、実際にはやりたいことをより効率よく実現できる方法をレビュアーを含めて考え直す機会としてレビューを使用することも多かったです。
実際にあったのは、ほとんど同じ処理を行っている2つのクラスがあって、それを共通化して1つのクラスにするべきか、しないべきかをメンバーで話し合いました。 その時は、同じ処理をしていてもそれぞれのクラスで役割が違うこと、後から読み返した時の理解のしやすさを考慮して共通化しないと決めました。 どうするべきかなかなか決めきれず時間もかかりましたが、最終的に理由をつけた上で方針を決定することができました。
やったことに対して指摘が入ることに抵抗を感じることもありますが、メンバーと話しながらより良いコードにしていく活動は開発する力を高めていく上で重要だと思います。
話し合いながらコードを書いていくことのメリット
オールアバウトでの開発は基本的にはペアプロで行われます。 チームのメンバーとペアを組んで1つのプログラムを書いていきます。 入社するまで、ペアプロをしたことがなかったので、思った以上にペアとずっと話しながら作業しているなと、メンバーのペアプロを見た時に思いました。
はじめてペアプロをした時は、使用している言語や設計に関して持っている知識と、コードを書いていくスピードの違いにメンバーとの大きな差を感じました。
知識に差があるのはどうしようもないので、自分でコードを書く際は具体的なコードの書き方を教えてもらったり、書いたコードに対してアドバイスをもらいながら実装を進めていました。 設計については、どんな設計でアプリを作っていけばいいのかなどを一緒に考えたりすることで、 開発に必要な技術的な知識と後々困らないような設計を考えることの重要さを学びました。
工夫したところとしては、スピードについていけていない、ペアの書いているコードが理解できない時はペアを組んでいる相手にそのことを伝えて、 分からないところや何を考えてコードを書き進めているのかを教えてもらうようにしていました。 こうすることで自分に理解のスピードを合わせてもらえてかつ、学習にもつながりました。
継続してインプットすることの大切さ
日常的にコードを書いたり、アプリを作ったりしていない状態で入社をしたので、勉強するべきことは非常に多かったです。 最初は使用している言語についての知識さえあればいいと考えていましたが、作ったものをサービスとして出していく上でそれ以外の技術も学ぶ必要がありました。 学んだことを列挙すると以下のとおりです。
- PHP
- MySQL
- Webで使用されている技術(HTTP)など
- docker
- kubernetes
- git
- テスト駆動開発
この中でも特に、Webアプリケーションを作る上で重要な、Webに関わる基本的な技術や、主に使用している言語であるPHPの基本的な書き方は入社する前から触れておいた方がよかったと感じています。
インプットの仕方は、業務中では新しく学んだことをメモして業務終了後に見直していました。 業務外では主に書籍を使って学習を進めていました。 勉強してたことをいくつか挙げておきます。
まだまだ学ぶべきことは多いのですが、教えてもらうことを理解しやすくなったり、自分でわからないことを調べるときの足がかりになったり、業務を進める上で役に立っていると思います。
3. 終わりに
今年どうだったか
1年目からAll Aboutの新規機能の開発に関わり、自分が何もできない状態であったことを知りました。 開発進める力を自分とメンバーで比較したときに、足元にも及ばないなと感じています。 ですが、業務の中で知識をつけたりメンバーに色々教えてもらう中で学べたことも多かったです。
来年度に向けて
1年ですごく開発ができるようになったわけでもないので、できることを増やせるような活動はしていきたいです。 すぐにできることは本や記事を読んでインプットすることですが、アウトプットする活動も意識してやっていきたいです。 現段階で構想はないのですが、何かアプリを作れるのが一番いいと思っています。 できることを増やして、楽しくサービスの開発することにつながればいいなと思います。
Always on CPU の導入体験談
こんにちは。オールアバウト SRE 所属 の@s_ishiiと申します。
今回は去年リリースされた Always on CPU を導入した事例をご紹介致します。
Always on CPU は非常に有益な機能でユースケースに合致する場合は効果を発揮します。
Always on CPU について事前知識の無い方はまずは以下をご一読ください。
https://cloud.google.com/blog/ja/products/serverless/cloud-run-gets-always-on-cpu-allocation
簡単に言うと以下画像のアイドル状態を無くすための設定です。
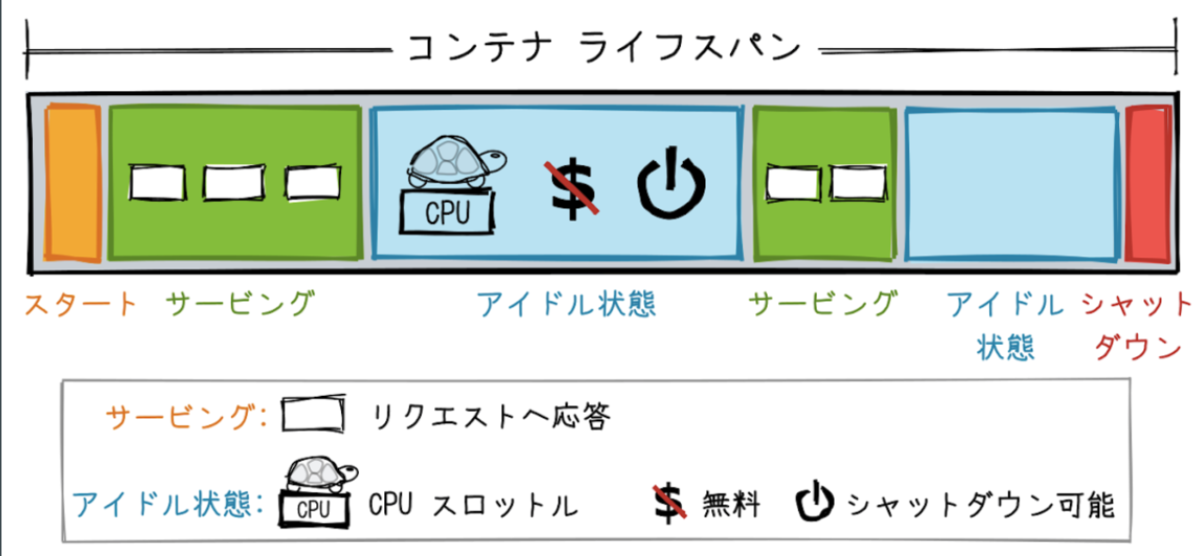
利用シーンとしては主に 2 つのケースがあります。
1. リクエスト受信後に非同期で処理を実行したい場合
Cloud Run 上で重たい処理を実行する場合、実際の処理は非同期で実行して HTTP のレスポンスは即座に返したい、といったケースは多々あると思います。
従来の Cloud Run はリクエスト返却後に CPU がアイドル状態に入ってしまうので非同期処理が行えなえませんでした(厳密に言うとすごく遅くなる)。
こうしたケースを Always on CPU を利用することでカバーできるようになったことで、Cloud Run の利用シーンが拡大しました。
2. リクエストを頻繁に受け付ける場合
もう 1 つは Web のバックエンドとして Cloud Run を利用している場合です。
この場合、リクエストを頻繁に受け付けることになると思いますが、Cloud Run の料金体系はリクエスト数に対して相対的に高く設定されているため割高になる傾向があります。
Always on CPU を有効化した場合、従来とは料金体系が根本的に変わりリクエスト数に対する課金が無くなります。 CPU の利用時間が長くなるのでその分の料金はかさみますが、リクエストが頻繁にくるような場合だと従来の Cloud Run の設定であっても CPU がアイドル状態になる時間帯が少ないはずなので結果として大幅な料金の削減が見込めます。
以下公式の料金表になります。Always on CPUではリクエスト料金が撤廃されていること、それに加えCPUやメモリの使用料金も下がっていることがわかると思います。
(CPUやメモリの料金が下がっているのは、常時起動するため単位時間当たりの料金を下げているのだと思います)
Pricing | Cloud Run | Google Cloud
私達が今回取り組んだのはこのパターン 2 になります。
対象となるサービスについて
おおまかに言うとアドネットワーク上で発生したログの到達先サービスになります。 サービスの利用規模としてはおおよそ以下の通りとなります。
- 月間リクエスト数:1 億以上
- 月間 CPU 時間:800 万秒以上
月間でかなり多くのリクエストをさばくサービスで、昼夜問わず動作している状態です。 また、Cloud Runのメトリクスを見ると課金対象のコンテナインスタンスが常に4つあることが分かります。

この調査をもとにAlways on CPU化対応することでCPU料金の上昇がほぼ発生せず、リクエスト料金分だけコストを削減できると判断し実施することになりました。
結果
Always on CPU化したところ期待通りリクエスト料金の分だけコストを削減することができました(元々の使用量の1/3まで低下)。 ほとんど作業を必要とせず(設定を切り替えるだけ)、ここまで大きな成果が出るのは素晴らしいと思います。
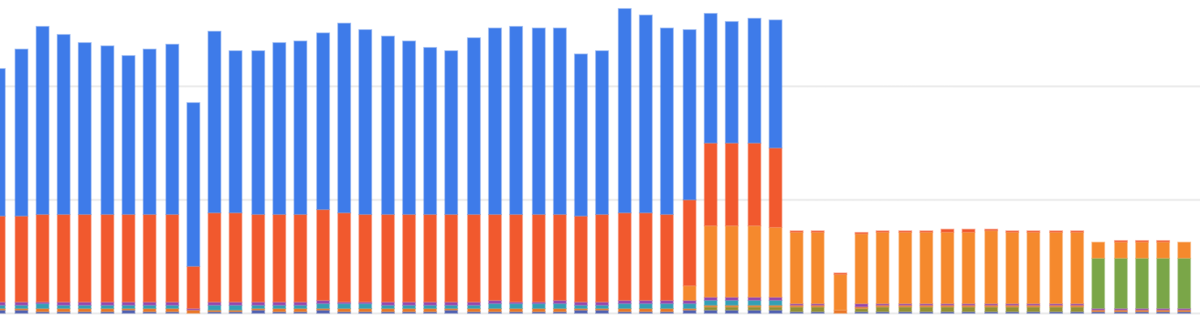
※ちなみに後半さらにコストが微減しているのは Cloud Run の確約利用割引を適用しているためです
是非Always on CPUが利用中のサービスのユースケースに合致するかご確認することをおすすめします。
なお、Always on CPU は 2022 年 2 月 時点では preview 版ですので導入の際はその点にご留意ください。
Google Cloud で Terraform を導入した話し
こんにちは。オールアバウト SRE 所属 の@s_ishiiと申します。
Terraform Advent Calendar 2021 の 25 日目の記事です。
この記事では Google Cloud で Terraform を導入した話しをご紹介します。
目次
- 導入の経緯
- 導入の流れとその後
- これからの課題
導入の経緯
オールアバウトでは Google Cloud を採用していますが、従来 IaC によるインフラ管理はされておらず手動で構築・運用されていました。比較的大規模なインフラを管理していることもあり、2020 年末の時点でこれ以上手動で管理していくことは不適切との結論に至りました。代表的な理由を以下にいくつかピックアップします。
1. 作業時の安全性
手動でインフラを管理する場合、新たに環境を構築・変更する時は手順書を作ってチームから承認を得て作業に移ります。これは安全な方法に見えるかもしれませんが、実際には作業時の操作ミスや作業者の勘違いで想定外の結果を生む余地があります。Terraform を利用することで事前に作業内容を明確にできるので、作業時の安全性が高まると期待しました
2. SRE メンバーに与えられた強すぎる権限
オールアバウトでは SRE がインフラを一元的に管理していますが、手動管理の都合上 SRE の各メンバーには Google Cloud への幅広い操作権限が与えられていました。これは人為的な事故を誘発するので、IaC の導入とインフラの構築フローを CD 化することによって SRE メンバーの権限を縮小化することが期待されました。
3. 命名規則の強制
サービス種別に応じた命名規則は整備されていましたが、実情として遵守されていませんでした。そもそも新しく SRE に加入したメンバーに命名規則が書かれたドキュメントを共有するフローになっていなかったので、人によっては命名規則そのものの存在を知らないといった事態になっていました。この経験から命名規則を徹底するにはドキュメント整備だけでは不充分で、CI のフローに組み込んで強制させる必要があると考えました。
上記のような理由に加え、当時 GKE クラスタのバージョンアップに伴うインフラ対応が控えていたため、これを期に Terraform を利用しようということになりました。
導入の流れとその後
ここからは Terraform の導入とその後どのように運用にのせていったのかを時系列順に記します。
STEP1. Terraform 導入
オールアバウトには大小 10 以上のサービスがあります。手動構築されたそれらのインフラ群を一度に Terraform のコード化するのは現実的ではないので、ひとまず新しく構築するインフラは Terraform を利用するとしました。
上述の通り、当時のインフラタスクに GKE クラスタの入れ替えがあったため、Terraform で作る最初のリソースとして GKE クラスタが選ばれました。またこれを機にコンテナ内で出力されたログを Cloud Logging のログルータ機能を使って GCS に保存することになったので、ログルータ周りのリソースも Terraform で構築することになりました。
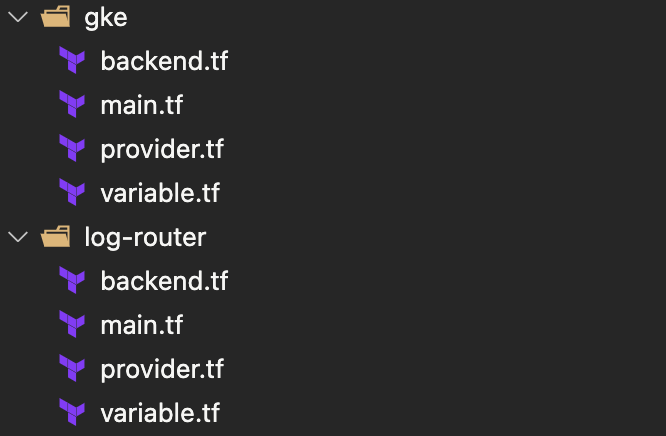
Terraform のディレクトリ構造
この時点では以下のように Google Cloud のリソース単位でディレクトリを分割して state ファイルを作成していました。しかし後になってこの設計は適切でないとの結論に至り、リファクタリングによって変更されることになります。
STEP2. リファクタリング
Terraform を導入して数ヶ月が経過すると、当初の Terraform 設計の問題点が露見してきました。なかでも以下 2 点が問題視され、改善することが望まれました。
- Google Cloud のリソース単位で state ファイルを分割している
- ステージング/本番環境のコードが分離されている
1. Google Cloud のリソース単位で state ファイルを分割している
当初は Google Cloud のリソースを state ファイルの分割単位としていました。単位として充分に小さく、かつ分割単位として明確という理由からこの方針が採用されましたが、実際に運用していくとリソース間参照がしづらくコードを書くうえで苦労しました。
Terraform で異なる state ファイルに記述されたリソースを参照するためには、参照元に output のコードを追記し、参照先でterraform_remote_stateブロックを用いて output されたリソースを取得する必要があります。これはコードの冗長化をもたらし、可読性と生産性を悪化させました。
https://beyondjapan.com/blog/2019/01/reference-other-tfstate-resource/
また当初メリットだと考えていた小さな state ファイル、という点も実際にはあまり恩恵を感じられず、むしろ 1 つのプロジェクト内に state ファイルが分散することにより、コードの更新内容を実環境に適用し忘れる事態が発生していました。
これらの点を踏まえ、state ファイルの分割単位を Google Cloud リソースから Google Cloud プロジェクトに変更しました。state ファイルの単位として大幅に粒度を拡大することになるので、チーム内で「もう少し小さな単位を模索したほうが良いのでは?」という意見も出ましたが、プロジェクトよりも小さい適切な単位を決めるのが難しかったこともあり、プロジェクト単位で state ファイルを分割することになりました。
2. ステージング/本番環境のコードが分離されている
これは書いてある通りで、当初ステージングと本番環境は別々のコードを書いて構築していました。このため時間経過とともに環境の乖離が発生し始めていたので、ステージングと本番で同一のコードを参照するよう実装を見直すことになりました。
リファクタリング後
以上の点を踏まえてリファクタリングした結果、以下のようなディレクトリ構造になりました。
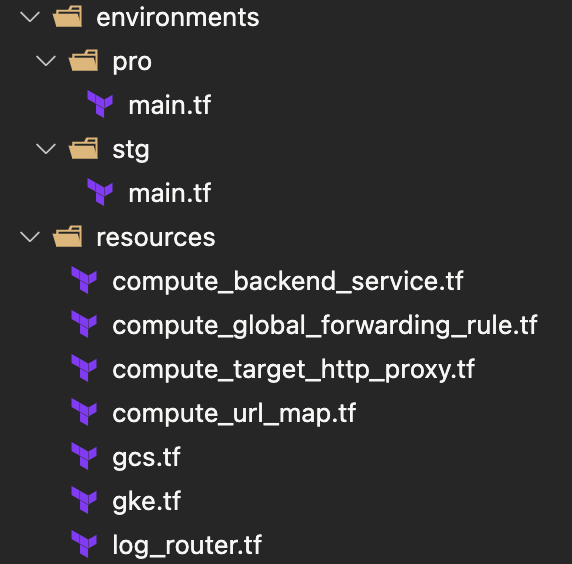
Google Cloud のプロジェクト毎にディレクトリを作成し、その配下に environments、resources ディレクトリを配置しています 。以下が main.tf の記述例です。resources 配下を module として呼び出しており、その際に可変値を埋め込んでいます。このように書くことで resources ディレクトリ配下にコードされた内容をステージング/本番で参照することになり、乖離が起きにくい実装になっています。
terraform { backend "gcs" { bucket = "BUCKET_NAME" prefix = "PROJECT_NAME/stg" } required_version = ">= 0.13" required_providers { google = { source = "hashicorp/google" version = "~> 3.53" } google-beta = { source = "hashicorp/google-beta" version = "~> 3.53" } } } module "stg" { source = "../../resources" region = "asia-east1" project_id = "PROJECT_NAME" env = "stg" }
STEP3. 手動構築したリソースの Terraform 化
ここまでで運用に耐えうる設計になったので(最低限ですが)、いよいよこれまで手動で構築してきたリソース群を Terraform 化することになりました。Terraform 化を進めるに当たって、以下 2 つの方針を前提に進めました。
コードは汚くて良い
Google Cloud で Terraform 化を進める場合terraformerが便利ですが、terraformer で自動出力されたコードの可読性は低いです。これを逐一リファクタリングしていくと相当な時間が消費されてしまうので、Terraform 化の作業のなかではリファクタリングは行わないことにしました。
全てのリソースを網羅しようとしない
オールアバウトがこれまでに構築してきたリソースは膨大なので、漏れなく Terraform 化しようとすると確認含め相当な時間を要してしまいます。目的は既存インフラを更新する際に手動ではなく Terraform で実行できるようにすることなので、更新頻度の低いリソースを頑張って Terraform 化する動機はありませんでした。そのため細部にはこだわず、Terraform 化対応で漏れたリソースは発見次第都度対応していくことにしました。
これらの前提のもと作業した結果、1 ヶ月程度で全環境を一通り Terraform 化できました。 しかしその一方で以下課題も残りました。
コードの可読性が低すぎる
リファクタリングしない前提で進めた結果、リソースの数が多いプロジェクトの可読性が相当低いものになってしまいました。今から考えるとその辺りはもう少し柔軟に対応しても良かったと思っています。
表記ゆれが目立つようになった
これは Terraform 化したおかげで気づけた点でもありますが、命名規則が徹底されていないせいで同じ種類のリソースで微妙に異なる名称が散見されました。これは for_each 等でループする際の障害になるので、将来のいずれかの時点で解消する必要が出てきました。
この 2 つの課題のうち、「コードの可読性が低すぎる」に対処するため週次でリファクタリング会を設け、チームメンバー全員で可読性の低い箇所を探してはリファクタリングしていくようサイクル化しました。
STEP4. impersonate 対応
当初の予定ではこの辺で Terraform の CD 化対応を進める予定だったのですが、他タスクとの優先度の兼ね合いに加え、全ての環境を 1 つの Terraform リポジトリにまとめているモノリポ構成であるため CD の工程が複雑になる等の理由で、CD 化は見送ることになりました。このため当面の間、Terraform は SRE メンバーのローカル端末で実行される状態が続くことになりました。
このような状況のなかで、かねてからの課題であった SRE に与えられた強すぎる権限を解消するために、Google Cloud の impersonate 機能を導入しました。これは事前に許可したサービスアカウントに成り代わることのできる機能で、この機能を Terraform のコードに導入してやると Google Cloud のコンソール画面からはリソース変更等の操作はできず、Terraform を経由した場合にのみ変更が可能になる、といったことが実現できるようになります。
https://cloud.google.com/iam/docs/impersonating-service-accounts
詳しいやり方は以下の記事で分かりやすく紹介されているので、興味のある方はご覧ください。
これからの課題
以上で Terraform を運用していく基礎はできたと考えています。一方で運用の容易性や優秀性を追求する余地もまだ多く残されています。具体的には以下のような課題があり、今後アプローチしていく予定です。
- terraformer で出力したコードのリファクタリング
- CI/CD の導入
- terraform-validator の導入
以上「Google Cloud で Terraform を導入した話し」でした。