Digital Native Leader’s Meetupに参加しました

こんにちは。株式会社オールアバウトでデータ基盤チームに所属している吉井です。
先日、Google Cloud 主催「Digital Native Leader’s Meetup」に参加してきました。
同名のイベントは昨年12月に開催されており、今回はその第2弾という位置付けとなっています。
第1弾については 株式会社 Magic Moment様の記事 が参考になるかと思います。
普段Google Cloudを活用してデータ基盤を構築しているエンジニアが、イベント参加者の視点で当日の様子をレポートしたいと思います!
Digital Native Leader’s Meetupとは
Google Cloudが主催したエンジニア向けの招待制Meetupイベントです。
これからのデータ戦略や、データ基盤の構築、運用を担うデータエンジニアやデータサイエンティスト同士が集い、語り合える場を提供します。
今回のテーマは「データアナリティクス」。
Google Cloud製品の最新アップデート情報や参加者同士のアンカンファレンス、さらにはデータにまつわるLTを通して、各社の事例や話を交換し合うことでプロダクト開発を加速させることが目的です。
場所はGoogle 渋谷オフィスでのオフライン開催ということで、オンラインのイベントが多い中、オフラインのイベントは大変新鮮でした!
会場の様子
飲み物はジュースからお酒まであり、食べ物も目移りするほど充実した内容...!
食べ物については一口で食べやすいラインナップとなっていて、イベントに集中できるような流石の配慮。

イベントトピック
Google Cloudから共有
詳しくは書けないのですが、Google Cloudユーザにとって嬉しい今後の情報と近年話題になっているデータメッシュのお話でした。
先行してGoogle Cloudのうちどこに注力しているかが分かるのは、ユーザ目線からしてもとてもありがたいです。
LT
普段から業務でGoogle Cloudを活用している企業様が、LT形式でデータの活用事例についてお話しして下さいました。
- 行動情報xBigQuery×大規模言語モデルで叶えるパーソナルコンシェルジュ
- BigQueryとRemote Functionsの組み合わせによってレコメンドエンジンを構築
- Data Analytics 製品の活用方法について
- Google Cloudのサービスをフル活用して社内外の要望に答えた
- アナリストではない本日参加しているGoogleメンバーがデータ分析にどう向き合っているか
- 営業職の方がデータをどう活用しているか
LTは第2回の今回から初めて設けられましたが、短い時間ながらも密度の濃い有益な情報盛りだくさんなお話でした。
まだまだGoogle Cloudを活用できる幅はたくさんあるのだということを痛感しました!
アンカンファレンス
事前のアンケートを踏まえてグループ分けされており、約40名の参加者が1グループ5,6人に分かれて主に以下のようなことについて話し合いました。

↓ Googleの社員さんがファシリテートし、各グループごとに白熱した議論をしている様子(プライバシー保護のため、写真にはぼかし加工を施しています)

イベント参加者全体だと、データエンジニアやアナリティクスエンジニアが多くの割合を占めていたと思います。
グループメンバー
私以外には、データ基盤を運用しているデータエンジニア、アナリティクスエンジニアを経て今はデータプロダクトのマネージャー、機械学習エンジニアなど多種多様な職種の方が集まっていました。
議題
- データの活用例
- 活用事例におけるGoogle Cloudのユースケース
- 課題に感じたこと、それに対する解決方法はどんなことをしたか
- 使っているGoogle Cloudサービスや最近気になっているサービスなど
具体的には
- データ活用側のリテラシーとどう向き合っている?
- Looker Studioでダッシュボード用意してどうにか対処しているなぁ
- データ基盤を整える上で困っていることがたくさんあって...
- ComposerやPub/Subにおけるサービス起因のデータ欠損に悩まされてる
- 膨大なデータを取り扱う場合のデータ整備って難しいよね
- → BigQueryでクエリの実行時間が大幅に短縮した
- リネージュなどを含めたデータへの理解不足をどう解決している?
- 会社におけるデータの位置付けは?
- 意思決定のためなので正確なデータは必要なく、ある程度の担保がされていれば良いとしている
行っている事業は違えど、皆さんデータに対して同様の課題を抱えており「いや、弊社もそれで困っていて〜」と共感の嵐。その上で「弊社ではこうやって対処していますよ」という風に解決策を議論していた有益な時間でした!
懇親会
イベント終了後、Google Cloudのすぐ近くにあるお店に移り、懇親会が開催!
参加者はGoogle Cloudの社員さんも含めて30人程で、人数がガクンと減りがちな懇親会でも参加率が高い印象を受けました。
私もですが、オフラインの貴重さをみなさん感じていたのでしょうか...?
懇親会では以下のようなトピックが話されていました。
- データメッシュ
- データの民主化
- データのコラボレーション(マーケットプレイス)
- 今後のイベントのアイデア
- データリネージ
- Cookieについて
- ガバナンス管理
- マスク
- 個人情報の保護
- 統一されたデータ
- データの正しい理解と使い方
- ChatGPTを主としたLLMの話題
- サービスへの活用
- 自社データによる信頼性の担保
- データの現在と未来の話
特に、トレンドのLLMや、最近特に注目されているデータメッシュやコラボレーションについての話題が熱く語られていました。 さらにはイベント好評につき、今後のイベントのアイデアの意見が出ていたりもしました。
参加者の中には様々な業種・役職の方が集まっていたかと思います。
ですが、アンカンファレンスや懇親会では最初の緊張感はあれど、次第に話が盛り上がっていき全員がお互いに意見を投げかけあっていたことがとても印象的でした。
やはり「データ」に関わる技術領域は広く、業種・役職関係なく話し合いたいことが数多く積もっているようです。
最後に
Google Cloudの活用事例やソリューションを数多く知ることができる、とても良いイベントでした。 特に、アンカンファレンスでは各社のデータ活用事例について有益な生の声を聞けたため、大変満足度が高かったです。
今回得たノウハウを自社のプロダクトにも活かしていきたいと思います。
新卒エンジニアとしての苦悩と成長

はじめに
オールアバウトグループの新卒1年目エンジニアが投稿する企画『テックブログ新卒週間2023』最終日4日目の投稿です。
株式会社オールアバウトでデータ基盤の運用・保守を行っている吉井と申します。
元々データに興味があり学生時代に分析や機械学習を学んでいましたが、データの基盤どころか、Webに関する知識も疎い状態でのスタートでした。
新卒として1年のうちにどんなことを学び、結果的にどんな成長を実感できたかをお話ししたいと思います。
チームの体制と業務内容
データ基盤グループにはメインで動けるのは2名、兼務の方が1名の合計3名が所属しています。
また、チーム全体で主に以下の業務を担当しています。
- データパイプライン(収集から加工処理、BIツールや外部アプリへのデータ送信といった一連のデータ処理の流れ)をメインとしたインフラの運用・保守
- BIツールを活用したデータビジュアライゼーションと他部署へのサポート
ですが、データ基盤グループが担う領域は幅広く、それ以外にも以下のようなことを行っています。
- 広告運用グループと直接やり取りしながらクライアント用のレポートデータを出力・共有
- サービス上で見たいデータについてのヒアリングやその対応
- 全社的にデータ活用をより推進するための促進活動
このような業務領域の幅広さに加えて、タスクの工程として以下のように構想から実対応までほぼ全てを自分達で行う形式を取っています。
- 自分達で課題を考え挙げ出す
- 課題の優先順位を決める
- 最終的にそれをどうやって対処するかを決める
- 実際の対応
そのため、適切な対処をするには業務知識だけでなく業界や技術的な知識など数多くのことを理解している必要があります。
これらの業務をメインで動けるのはマネージャーと自分の2人という状況もあり、不安を抱えながらもやれることの多さに胸を踊らせながらチームにジョインしました。
一年の流れ
知識を身に付けていた前半の期間と、その知識を実践に活かす後半の期間に分けてお話しします。
前半 ~学び編~
早速ですが、アプリケーションの開発とは異なり、データ基盤はなかなか実際に手を動かしながら学ぶということが難しいです。 体系化されている他社さんもいらっしゃるかもしれません。 ですが、少なくとも弊社では経験のあるエンジニアがデータ基盤を担当してきた経緯があり、私のような知識がない新人が自分の力だけで理解を進めるための地盤は確立されていませんでした。
実際に行った業務知識の付け方としては、とにかく地道に見て学んで疑問があったら質問をするという手当たり次第な方法です。
データパイプラインのアーキテクチャを学び、マルチクラウドであるため様々なクラウドサービスやいくつかのBIツールなどに簡単に触れてみることから始めました。 データの流れや意図を知るには自社サービスの仕組みや実際の画面上での操作も知っておく必要があるため、そういったことを教えていただきながら少しずつ知識を蓄えていきました。
課題とその解決
1.業務理解
始めは、得た知識が一般的なことであるのか自社独自の仕組みなのかが判別しきれず、業務知識を理解する際の妨げになっていたことが課題に感じていました。
このような問題に対しては積極的に状況の切り分けを目的に質問してみたり、一般的なことであれば自分で調べ、ユースケースを自分なりに理解し、自社状況に改めて落とし込むということを行うことで一歩一歩解決していきました。
2.データ構造とモデリング
また、データ基盤の3層構造(データレイク・データウェアハウス・データマート)を採用しており、主に Treasure Data と MySQL の2つの環境を利用しています。
- Treasure Data : ログデータの蓄積と加工
- MySQL : 最終的に用途に合わせてテーブルごとに集計されたデータを格納
ここで強く課題に感じたことは、あるデータを抽出したいとなった時に「どちらの環境のどのDBのどんなテーブルからどんな条件でデータを取ってくればいいか」という判断がとても難しいということでした。
この課題に対して、まず大枠の環境ごとに格納されているデータの役割を理解し、その中の各層に分けた上でこの層とこの層との間では何を目的にどういった処理をしているかといった意味を理解するよう努めました。 これにより、対象のデータが欲しい時は大体ここを見にいけば良い、という感覚を身に付けることができました。
後半 ~実践編~
色彩あふれる紅葉が見られるようになった10月頃のことです。
データの収集から最終的な活用先のイメージが付いてきたため、既存のデータ基盤の改善や社内でのBIツールのサポート等を実際に行いました。
良かったこと
開発用に作った環境は数知れず、と言えるほど多くの環境を作り上げる経験をしました。 基本的に、何かを検証をしたり技術的な調査をするときには都度GCEを使って立ち上げた新たなインスタンスに環境を構築したり、ローカルにDocker環境を作った上で作業を行っています。
もちろん適宜分からないところは追加で調べたりしましたが、前半期にデータにまつわることと並行して学んでいた Docker の基礎知識が大変役に立ちました。 Docker はエンジニアにとって今や普遍的な技術となっているため、業務を通して最低限使いこなせるようになり、それを自分で試行錯誤してみる経験ができたのは1エンジニアとして良い財産になると感じています。
大変だったこと
私は、データ基盤の改修を目的としてdbtというワークフローツールの調査・共有を基本的に一人で行いました。 ですが、自社のアーキテクチャとの相性が悪く、色々なことを加味して今は組み込むことができないという結論に終わってしまいました。 dbtはモダンデータスタックとして最近注目が集まっているツールでありデータエンジニアとして楽しみにしていた部分と、自分が調査したゴールが「現状では導入できない」というチーム全体にとっても悔しい結果に終わりました。
この出来事は、会社やチーム全体の今後のことも踏まえた上で意思決定しなくてはいけないという業務の難しさを味わった瞬間でした。
業務以外の活動
業務とは別に以下の2つを継続的に行っています。
- 勉強会 : 月に平均して3,4つの勉強会への参加または視聴をし、要約や感想・疑問をアウトプットとして times に投稿
- 単語帳 : 口頭で誰かに説明するには自信がないような理解不足な単語をとにかくシートにまとめて、ひとつひとつ調べていく
勉強会は主にデータにまつわる技術的な内容をカバーする目的です。 昨今ではアーカイブが残る勉強会も多くなり、活かせるものは活かして効率的に知識の獲得に繋げました。
単語帳に関して、自社で現在扱っているものは学ぶことができますが、優先順位的にまだ触れられていない技術やそもそも現在の業務だけでは得られない知識がたくさんあります。 以下のような技術的なことから一般的なことまで、領域を定め切ってしまうのではなく、とにかく気になったものは何でも楽しく身に付けようという意識で学びました。
- 他社でのデータパイプライン・データモデリング
- データ活用やサービスのユースケース
- 様々なサービスやツール
- ビジネス用語
- コンピュータサイエンス
- アプリケーション開発
単語の数はこの1年を通して700を超え、自分でも驚きと達成感を感じています。 また、密かに目標にしている、自分の業務とは直接関係ない話の輪に入ることができる状態も目指して、今後もこれらの活動は続けていこうと思っています。
成長を感じた出来事
一年間業務を通して様々な経験や学びがあったと同時に、まだまだ未熟だと感じる時はあります。 ですが、業務を通して得られた知識はもちろんのこと、自主的に学んできたことがきちんと身に付いていると確かな実感として持てた瞬間もありました。 それは、3月24日に Google 主催の Digital Native Leaders Meetup という、データにまつわる GCP サービスのアップデート情報や各社のユースケースについて話し合うオフラインイベントに参加してきた時のことです。
イベントの参加レポートは後日、このテックブログで公開させていただきたいと思っています。
そこで、新卒の身でありながら他社のエンジニアの方々に対して対等に議論できるようになっていることに気付きました。 一年前の自分が参加していたら、議論どころか言葉の意味も分からず聞くことに徹していたと思うと、確かな成長を感じた出来事です。 また、その議論を通して他社の方からも、新卒なのにデータのことにとても詳しいとお褒めの言葉をいただき、この一年やってきたことがきちんと身に付いていることを実感しました。
おわりに
これからは「新卒なのに」の部分が無くなります。 今後は一人のデータエンジニアとしてより深い知識と経験を身に付け、自分なりの価値を提供していきたいと思います。
オールアバウト新卒エンジニアが1年で学んだこと

はじめに
初めまして、株式会社オールアバウトでWeb開発をしている@r_chibaです。
2022年度から新卒のエンジニアとして働きはじめて早1年経ちました。今回は業務をしていく1年間の中で、苦労したことや学んだことや、日々の業務をどのように行っているかなど、色々とつづっていければと思います。
自己紹介
小学~高校までは愛知県で過ごし、大学からは長野の大学で学生生活を過ごしていました。 大学の専攻は理系分野ではありましたが、Webエンジニアとして使用していくプログラミングに関しての授業などはあまりなく、 大学2年時にC言語の授業を受けたぐらいでした。その時の授業でもポインタなどの説明を受けて、よくわからなかったことを覚えています。 大学院1年時にWeb系のプログラミングに興味を持ちはじめたのがきっかけで、自分でサービスを何かつくってみたいと思い、Ruby on Railsという フレームワークを用いて、大学の授業を評価するためのサービスや、自分のblogを作ったりしました。 自分は小学~高校までサッカーをやっていた、体育会系の人間で、あまり自分で何かを作ったりするといったような経験が少なかったのですが、 そういったサービス作りの経験から、ものづくりの楽しさをジワジワと感じ始め、エンジニアを目指そうと思い、オールアバウトにエンジニアとして入社しました。
業務内容
開発部で、Web業界における広告代理店とメディアをつなぐプラットフォームサービスの開発に携わっています。 広告代理店は、商材を売りたいクライアントと商材を宣伝するメディア間との仲介となるものなのですが、その広告代理店とメディアとの間では スケジュール調整や、非一元的な情報管理・連絡方法等の、雑多・煩雑な業務だったりの課題点が多くあります。 そのような広告代理店とメディアとの間のDX化を推進するための、サービスづくりを日々行っています。 現在は新機能開発の要件定義・設計・開発のタスクを任せていただいております。 業務を行う上で、やりたいと手を挙げたタスクに携われたり、自分の意見がサービスにとって良いものだったときは、その意見が実際にサービスに取り入れられて、反映されたときには、とてもやりがいを感じます。
業務スケジュール
私のある日の業務スケジュールです。基本的にリモートワークで、金曜日の会議が多い日は出社します。 日によって細かい違いはありますが、実装を重点的にやる日はこんなスケジュールです。
9:30~ slackで出社連絡。メールやスケジュールを確認して、1日の動きを把握する。
9:45~ 開発メンバーで朝会。それぞれのメンバーが1日どんなことを行っていくかなどの動きを確認する。
10:00~ ペアで実装
12:00~ お昼休憩。たまに散歩にいったりして、気分転換をする。
13:00~ ペアで実装
17:00~ コードレビュー
17:30~ メンタータイム。メンターの方と1日の振り返りなどをしたりする。
18:00~ 夕会。開発メンバーで1日の振り返りや、連絡事項を確認。
18:30~ slackで退勤連絡
私のチームでは主にペアプログラミングの体制をとっています。ペアプログラミングは、2人がペアを組んでプログラミングを行なっていく方法なのですが、 1人がドライバと呼ばれる、実際に手を動かして実装をしていく役割の人と、もう一人がナビゲータと呼ばれ、実装の方針などをドライバに指示する役割を担っています。 私が配属された当初ではすでにチームでペアプロで行なっていく体制ができあがっていましたが、在宅勤務が始まる前は部分的にペアプロを取り入れていて、在宅勤務に切り替わったのをきっかけに、ほぼ全ての実装をペアプロに切り替えていったそうです。背景としては、在宅勤務によるコミュニケーション量の減少や、レビュー工数の削減などがあったみたいです。
苦労したことや学んだこと
ペアプロ
主に配属当初は実装力強化を目標としていたこともあり、ペアプロではドライバーを担当させていただく割合が多かったのですが、ドライバーとしてやっていく中でいくつか苦労した点がありました。まず実装力の点で、実装方法がわからず手が止まってしまってしまうことが多く、気持ち的にも焦ってしまうことがありました。そこで教わったこととして、やりたいことを書き出してみる、そして書き出したやりたいことに対して、必要なことを分割してさらに書き出してみるといった方法です。これは分割統治法と呼ばれる問題解決手法で、難しい問題を細かく分割することで、一つ一つの問題の難易度を単純なものにするというものです。分割統治法はプログラミングにおける大切な考え方の一つであり、自分自身、物事を処理できるワーキングメモリの容量もそれほど大きいほうではないと感じていたので、こういった方法はとても役立ちました。また、実際に自分がやりたいことを口にだしながら、書き出していくと言語化されていなかった部分も自分の中で整理できて、気持ち的にも落ち着ける効果もあり、現在も行き詰まったときはまずは書き出してみて、一つ一つ処理していくことを実践するように心がけています。
次に、コミュニケーション面で難しいと思った点が、自分が実装しようとしていることをうまくペアの人に伝えられなかったという点です。 理由としては何点かあり、実装方法を考えることに必死で、コミュニケーションをとる余裕がなく、口数が少なくなってしまったことや、実装方法が自分の中でも明瞭に整理できておらず、言語化しようとしたときにできないといったことなどが考えられました。一つ目の実装にいっぱいいっぱいになってしまうことに関しての改善方法としては、実装に入る前にあらかじめ実装ができなさそうな点があれば予習をしてくる、ということを実践しました。予習をしてくることで、余裕が少しだけでてきて、相手にも伝えることが少しずつできるようになっていけるようになってきたのかなと思います。2つ目の言語化できないといった点に関しては、上に挙げたやりたいことを口にだして書き出してみるといった方法で日々できるようになってきたと感じています。
コードの規模
それまで個人で開発していたコードは、ファイルの量やコード行も少なく、管理もしやすく、修正も容易でした。しかし、チーム開発に参加すると、他のメンバーが書いたコードを読むことになり、ファイル量やコード量もかなり感じました。その規模の大きさに驚き、どこから手をつけていいのか、何を見ればいいのか戸惑いました。 また、チーム開発では、複数人で同時に同じコードを編集することもあります。その際には、コンフリクトが発生することもあり、手順を守りながらコードをマージしていく必要がありました。個人開発では考えられないような、コミュニケーションや手順の重要性を痛感しました。 しかし、チーム開発を続けるうちに、規模の大きなコードでも、コードの構造やコメントを活用することで読みやすくなることに気づきました。また、チーム開発におけるコミュニケーションの大切さを学び、チームメンバーとの協力や相談を通じて、コードの改善に取り組むことができました。
インプットの多さ
とにかく新しく学ぶ情報が多かったです。技術的なところにとどまらず、リリースやマージでの細かい作業・日々チームとして働いていくための決まりごとなど、当初はインプットする必要のあるものが多くあり、学んだことはメモをとり、次の日の朝に軽く見返すといったことをしていました。 最初はインプットすべきことが無限に感じ、少し不安になることもありましたが、業務を開始して半年ほどたったころから少しだけ心に余裕のない状態から抜け出し、学んだこと一つ一つに対してじっくり考える余裕も少しずつでてきたのかなと思います。
見積もり
私の部署ではアジャイル開発を導入しており、2週間に一回タスクをいただく機会があるのですが、その際にタスクにかかる見積もりを出す必要があります。 この見積もりというものが最初はとても難しく、見積もり段階では2時間かかると思っていたものが倍の4時間かかったりと、想定よりも見積もり時間がオーバーしてしまうことを課題点に感じました。なので、見積もり精度を向上させなければと思い、どのように見積もりを立てているかを先輩に伺ったところ、タスクの粒度を細かくすることが大切と教わりました。当初は全体で〇〇時間かかりそうというぼやっとした憶測で見積もりをたてていたのですが、タスクを細かく分割して、「この実装のためにはこの関数とテストが必要で、全部足したら〇〇時間かかる」といったふうに、詳細な実装イメージを持ちながら行うといいと知り、見積もり精度の向上に役立ちました。 見積もり精度はまだまだ改善の余地があるので、日々立てた見積もりのズレに対して原因を考えていき、精度向上に努めていければと思います。
技術力向上のためにしたこと
自分で手を動かし、アプリを作る
実装力が当初なかったことを課題に感じていたので、どうやったら力がつくだろうと色々と調べたり、先輩に「どうやったら実装力つきますか?」と聞いたりして、自分が実践していく中で一番しっくりと来ているのは、わからないことがあったり、作ってみたいものがあったら「実際に手を動かして作ってみる」です。自分の手を動かさず、コードを読んだり、知識を蓄えるインプットだけだと、理解したような気分になり、いざコードを書こうと思うと、思ったように手が動かないことが多々あります。実際に手を動かしてみることで、実現したいことに対しての検索をし、コードに落とし込む実践力だったり、コードを書いていく中で、悩む点が出てきてここはこうしたほうがよさそう、とコードをどんどんと改造していくことを学んだりできます。そういったことをしていると、他の人が書いたコードが自分が悩んだ点を最適化するように実装されていることに気づいたり、逆に自分だったらこう書くのにといったふうに自分なりの考えもでてくるようになり、色々メリットを享受できていることを感じられたので、このシンプルだけど、強力な方法は私の中でしっくりときています。 マイクロソフトで働き、現在のosに多く採用されているダブルクリックやドラッグ&ドロップを生み出した日本人エンジニアである、中島聡氏も「僕は何かを学ぶ際は必ず手を動かしながら、考え学んでいる」とおっしゃっており、優秀なエンジニアも頭の中だけで考えず、実際に手を動かして学んでいたりします。
私が具体的に行ったことは、業務の中で自分自身が苦手と感じていることや、学びたいと思っている技術分野のアプリを作ったりしました。 以下に私が作成したアプリを紹介してみます。
Pomodoro timer
Pomodoro timerとはタスク集中手法の一つです。人間の集中力の限界は25分といわれているのですが、pomodoroは25分作業5分休憩をワンセットにし、集中力をできる限り切らさずにタスクを行うことができます。 このpomodoro timerのアプリを作った理由は、当時業務を行う中でJavascriptを触る機会が多かったのですが、手が止まることも多く、Javascriptに慣れるためになにか自分の手で動かして作ってみようと思ったがきっかけです。
Firebase Realtime Databaseを使ったリアルタイムアプリケーション
Firebase Realtime Databaseとは、Googleが提供しているFirebaseと呼ばれるプラットフォームのサービスの一つであり、リアルタイムアプリケーションを効率的に構築することができます。業務でもこのサービスを使用したので、勉強のためにこの技術を使ったWebアプリを作ってみました。 タスク管理系(trelloみたいな)のアプリをJavascript、Laravel、Firebase Realtime Databaseを用いて作成したのですが、実装していく中で、Firebase Realtime Databaseの使い方や、Javascriptのファイル管理の方法を考える機会もあり、いい学びになりました。 また、オールアバウト全体の開発部勉強会が月に1回開かれるのですが、その勉強会に登壇した際に、このアプリで苦労したことを共有した際に、 色々とフィードバックをいただき、勉強になりました。
学んだこと
はじめてアプリづくりをするときは何を作っていいのかわからなかったり、また、誰も作ったことのないサービスをつくる必要があるのでは最初は思ったりしましたが、最初は気負わずに世の中にあるアプリを真似たものでも、本当に簡単なものでいいなと思いました。上に挙げたpomodoro timerもweb上サービスとして既にあるものですが、実装をしていく中で新しい発見や自身の実装力向上のいい機会になったと感じています。まずは、自分が実現したいと思ったものをコードに落とし込んで、形でできるようになることが、エンジニアとしてのファーストステップであるのかなと個人的に思います。
最後に
今回は、自分自身が新卒エンジニアとして働いている1年間の中で、苦労したことや学んだこと、業務内容や日々の業務について紹介しました。 この1年間で学んだことを活かし、今後もさらに成長していけるよう、日々努力していきたいです。
GCPを1ミリも知らなかった新卒が業務で学んだ知識でデプロイできるようになるまで

はじめに
オールアバウトグループの新卒1年目エンジニアが投稿する企画『テックブログ新卒週間2023』2日目の投稿です。
オールアバウトでPrimeAd関連サービスの開発をしているhinakochiです。 サービスの一つのリビルドに関わる中で、アプリをGKEでデプロイする経験をしました。入社するまでGCP自体ほぼ触ったことがなかったので、当時はついていくので精一杯になってしまいました。改めて何が起こっていたのかを理解するため、一度最初から最後までを自分でやりきりたいと思いました。約3ヶ月間、主に平日に一日一時間程度を使って簡単なアプリのデプロイに挑戦してきたので、これを機にその過程と学んだことをまとめてみました。遠回りが多くできたことはごくわずかですが、少しでもどなたかの参考になれば幸いです。
使用したもの
コンテナとアプリ構成: php-fpmコンテナ(appサーバ) + nginxコンテナ (webサーバ) + CloudSQL (dbサーバ)
Laravelのappコンテナとリバースプロキシ用のnginxのwebコンテナを自作イメージを使って立てます。これは業務で関わったものとほぼ同じ構成です。データベースには、本番ではCloud SQL Auth Proxyで接続します(ローカルではMySQLコンテナを立てていました)。 今回はデータベースに保存したテキストを取得して表示する簡単なテストページを用意しました。外部IPアドレスに接続してこれが表示できればゴールとします。
最終的な構成のイメージはこのようになります。
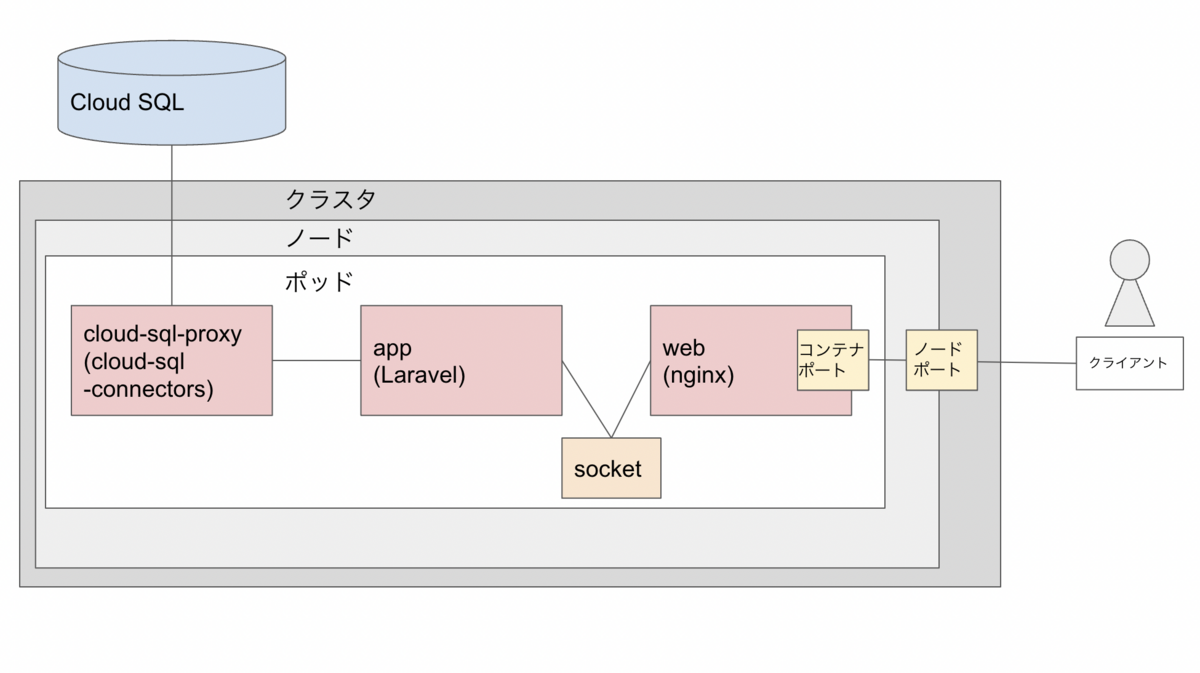
GCPで使用した主なサービス
Kubenetes Engine
コンテナの自動管理ツールです。コンテナの集合体の最小単位をポッド、ポッドを実行するマシンをノード、ノード群をクラスターと呼びます。マニフェストファイルでポッドの構成やスケーリングの条件などを定義しておき、リクエストに応じて自動的にスケールさせることができます。
Cloud SQL
クラウドベースのリレーショナルデータベースシステムです。
Container Registory
コンテナイメージを保存・管理できるサービス。ただしイメージのストレージ自体はCloud Storageが担っています。(現在はOSパッケージなども保存できるよう拡張されたArtifact Registoryが推奨されています。参考:Container Registry のドキュメント)
IAM
サービスというより、GCPの各サービスを使用するためのアカウント体系です。個人、組織、サービスなどの固有のアドレスをプリンシパルという概念で並列に扱い、様々な権限を付与します。個人的にはここで一番よく引っかかりました。具体的には、足りない権限が何か、それをどう与えるのかがわからない、IAMのサービスアカウントとKubernetesなどサービス特有のアカウントとの関係がわからないなどの点で悩みました。
ちなみに90日間30$分の無料トライアルを利用しました。実は間に合わず期限後少しだけアップグレードすることになったのですが、クレジットが残っている分は引き継げるので大した負担にならなくてよかったです。
その他
GitHub Actions
CI/CDツール。コードもGitHubで管理しています。
Kustomize
Kubernetesのマニフェストファイルを複数まとめて管理できるツールです。参考にしたチュートリアルに登場したので試しに触ってみました。今回はデプロイ環境を一種類しか用意していないのでそこまでメリットはないのですが、ベースのマニフェストファイルを動的に書き換えて使う方法を学べました。
やったこと
実際の手順を辿りながらハマった部分をピックアップしていきます。ローカルで動くアプリは一旦完成している状態です。
デプロイ前のGCP側の準備
プロジェクト作成
ブラウザの管理コンソールで作成しました。 プロジェクトはKubernetesに限らずGCP内の様々なサービスに跨がります。
API有効化(Container Registory, Kubernetes Engine)
gcloud services enable \ containerregistry.googleapis.com \ container.googleapis.com
これで該当サービスが使えるようになります。 この時点でデータベースの実現方法は一旦置いていたのでCloud SQL周りはまだ何もしていません。 このあたりの工程から下記の記事を参考にさせていただきました。
GitHub Actions を使用してGKEにアプリケーションをデプロイする
Kubernetesクラスタ作成
Kubernetesクラスタは作成の際、標準モードとAutopilotモードを選択できます。Autopilotモードは設定しなくとも自動スケーリングやノード管理をある程度やってくれるようです。せっかくなので使ってみましたが、小規模なアプリなので特に恩恵はなかったと思われます。
クラスタ作成の過程で誤って飛ばしてしまい、その結果長時間悩むことになったステップを紹介します。
# クラスタの認証情報を取得する gcloud container clusters get-credentials sample-cluster-name \ --zone zone-name --project sample-project-name
KubernetesのCLIツールであるkubectlを使用するにはクラスタを選択して接続する必要があります。 この設定ができていないうちは下記のようなエラーが出ており、次のセクションで出てくるような個別のロールの設定が必要なのかとしばらく誤解していました。
Error from server (Forbidden): deployments.apps "deploy-***" is forbidden: User "***" cannot get resource "deployments" in API group "apps" in the namespace "default": requires one of ["container.deployments.get"] permission(s).
サービスアカウントの設定
# サービスアカウント新規作成 gcloud iam service-accounts create sample-project-service-account # プロジェクトに対してサービスアカウントとロールを紐づける gcloud projects add-iam-policy-binding sample-project-name \ --member=serviceAccount:sample-project-service-account@sample-project-name.iam.gserviceaccount.com \ --role=roles/container.admin --role=roles/storage.admin # サービスアカウントキーを作成&出力 gcloud iam service-accounts keys create key.json \ --iam-account=sample-project-service-account@sample-project-name.iam.gserviceaccount.com cat key.json | base64
サービスアカウントは各サービスを利用するためのアカウントです。サービスアカウントにプロジェクトにおけるロールを与えると、ロールによってできることが追加されます。container.adminはKubernetes Engineのオブジェクト全般に対する管理者、storage.adminはCloud Storageに対する管理者ロールです。Cloud Storageはプロジェクト内のオブジェクトを保持するストレージサービスなのでこちらの権限も必要になります。 出力したサービスアカウントキーはGitHub Actions側でsecretsに登録し、Actionsから操作できるようにします。 ※今回は個人的な学習目的の環境なので大きな問題はありませんでしたが、最近はサービスアカウントキーをCI/CDツールに登録することのリスクが指摘されています。GitHub Actions OIDCや後述のWorkload Identityなどを利用して直接サービスアカウントキーを登録せずに運用することができます。弊社がGitHubで管理しているサービスはGitHub Actions OIDCを利用しています。
appコンテナとwebコンテナのデプロイ
Kustomizeの設定
ファイル構成は以下の通りです。
deploy/
- kustomization.yaml
- deployment.yaml
- service.yaml
kustomization.yaml
apiVersion: kustomize.config.k8s.io/v1beta1 kind: Kustomization resources: - manifest.yaml - service.yaml images: - name: web-image - name: app-image
# kustomization.yamlのあるディレクトリに移動 cd deploy # app-imageというイメージ名変数に使用したいイメージ名を設定 kustomize edit set image app-image=gcr.io/$PROJECT_ID/$IMAGE-app:latest # web-image kustomize edit set image web-image=gcr.io/$PROJECT_ID/$IMAGE-web:latest # deployment等を作成してそれをもとにリソースを更新 kustomize build . | kubectl apply -f
kustomize edit set imageでkustomization.yamlで用意した変数にイメージ名を設定し、変数が置き換わった状態でbuildすることができます。
deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sample-project
labels:
app: app-name
spec:
replicas:
selector:
matchLabels:
app: app-name
template:
metadata:
labels:
app: app-name
spec:
serviceAccountName: sample-ksa
containers:
- name: web
image: web-image # kustomize edit set imageで更新
ports:
- containerPort: 81
volumeMounts:
- mountPath: /var/run/php-fpm
name: nginx-sock
- name: app
image: app-image # kustomize edit set imageで更新
volumeMounts:
- mountPath: /var/run/php-fpm
name: nginx-sock
# 後略
ちなみに、次のコマンドもbuildができるのですが、buildした結果のdeploymentが出力されるのでデバッグに役立ちました。
oc kustomize
正しいイメージを使用できているかの確認
デプロイが成功したらまずこれが大事だと振り返ってみて思います。私の場合は、Podが動いていなくてPodの設定まわりを確認するのに時間を費やしてしまったのですが、実はイメージがpushできていない、イメージを指定できていない、古いイメージを使ってしまっているなどのミスがありました。 前セクションのocコマンドで最新のdeploymentを確認できるほか、ターミナルから次のコマンドで実際のPodで使用されているイメージを含む様々な情報を確認できます。
kubectl describe pods pod-name
コンテナ間通信
今回はUnixドメインソケットを使用しています。Unixドメインソケットを用いた通信はTCP通信より高速で、同じマシン内であればデータ通信用のファイルパスを通すことで通信できます(今回はappコンテナとwebコンテナが同一のマシンに乗っている状態なのでこの方法が可能です)。GCPとは話がずれますが、こちらもうまく接続できるまで非常に時間がかかった部分なので、どなたかの参考になることを願い簡潔に残しておきます。
deployment.yaml
apiVersion: apps/v1
kind: Deployment
# 中略
containers:
- name: web
image: web-image
ports:
- containerPort: 81
volumeMounts:
- mountPath: /var/run/php-fpm
name: nginx-sock
- name: app
image: app-image
volumeMounts:
- mountPath: /var/run/php-fpm
name: nginx-sock
# 中略
volumes:
- name: nginx-sock
emptyDir: {}
上記の設定では、nginx-sockというボリュームを確保し、コンテナごとに設定したパスでマウントします。 次はnginx側の設定です。
web/default.conf
server {
listen 81; # webコンテナ containerPortの数字
server_name example.com;
root /data/public;
# 中略
location ~ \.php$ {
fastcgi_pass unix:/var/run/php-fpm/nginx.sock; # ソケットファイルパス
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
include fastcgi_params;
}
# 中略
}
appコンテナ側では、ソケットファイルにアクセス可能なシステムユーザーを用意する必要があります。
app/www.conf
[www] listen = /var/run/php-fpm/nginx.sock # ソケットファイルパス user = nginx # ユーザー設定 group = nginx listen.owner = nginx # listenに使用するユーザーを設定 listen.group = nginx listen.mode = 0660 # 後略
app/dockerfile
FROM php:8.2-fpm ENV TZ Asia/Tokyo RUN apt-get update && \ apt-get install -y git unzip libzip-dev libicu-dev libonig-dev && \ docker-php-ext-install intl pdo_mysql zip bcmath # ユーザーを作成する RUN addgroup --system nginx && adduser --system --ingroup nginx nginx COPY ./docker/app/php.ini /usr/local/etc/php/php.ini # confファイルを配置 COPY ./docker/app/www.conf /usr/local/etc/php-fpm.d/zz-www.conf COPY . /data RUN chmod 777 /data/storage -R COPY --from=composer:2.0 /usr/bin/composer /usr/bin/composer WORKDIR /data
confファイルをzz-www.confという名前に変更していることに注意してください。ここで使用している公式イメージでは、ビルド時にデフォルトのwww.confで上書きをしてしまう仕様があるようです。辞書順で後ろになるファイルを用意すればその内容が優先になるため、名前を変えて対応できるということのようです。 参考: PHPの公式DockerイメージでUNIXソケット通信しようとして罠にハマる
外部アクセス
service.yaml
apiVersion: v1
kind: Service
metadata:
name: sample-project-service
labels:
app: app-name
spec:
type: NodePort
ports:
- port: 81
nodePort: 30080
selector:
app: app-name
次のコマンドで得られる外部IPとnodePortの値をコロンで繋いで接続できます。
kubectl get nodes -o wide
Cloud SQLの初期設定
API有効化
gcloud services enable sqladmin.googleapis.com
Cloud SQLのインスタンス作成
これだけ管理コンソールで作成しました。MySQLを選択したほかはデフォルト設定です。 データベースはLaravel側でマイグレーションファイルを用意しています。
Cloud SQLのユーザー作成
gcloud sql users create sample-db-user \ --instance=sample-db-instance --password=sample-db-password
Cloud SQLの接続設定
サービスアカウントにロール追加
# Kubernetes Engine管理者ロールのあるサービスアカウントにCloud SQL接続クライアントのロールを追加 gcloud projects add-iam-policy-binding sample-project-name \ --member=serviceAccount:sample-project-service-account@sample-project-name.iam.gserviceaccount.com \ --role=roles/cloudsql.client
ここからのステップは以下の公式ドキュメントの「Secret オブジェクトを作成する」「Cloud SQL Auth Proxy にサービス アカウントを提供する > Workload Identity」を参考にしています。
Google Kubernetes Engine から Cloud SQL への接続について
Cloud SQL Auth ProxyとはIAMを用いた認証でCloud SQLに接続するためのコネクタです。今回はこのコネクタの公式イメージを使用してPodにコンテナを生成して接続します。
Secret オブジェクトを作成する
Kubernetesで使えるkey-value型のオブジェクトを作成します。後ほどマニフェストに使用します。
kubectl create secret generic sample-db-secret \ --from-literal=username=sample-db-user \ --from-literal=password=sample-db-password \ --from-literal=database=sample-db-name
Workload Identityを有効化する
Workload Identityとは、Kubernetesのクラスタ内のサービスアカウントにIAMで作成したサービスアカウントを紐づけて接続する仕組みです。認証回数が減る、サービスアカウントキーを保持する必要がなくなる、アクセス範囲を狭められるなどのメリットがあります。appコンテナとwebコンテナはまさにサービスアカウントキーを使用してしまったので、Workload Identityを用いた改善の余地があります。こちらは今後の課題とします。
Autopilotモードでクラスタを作成すると、デフォルトで有効になっています。
Kubernetesのサービスアカウントを作成する
kubernetes-service-account.yaml
apiVersion: v1 kind: ServiceAccount metadata: name: sample-ksa
deploymentなどと同様にマニフェストファイルを作成し、applyすることで作成されます。
サービスアカウント同士を紐づける
# KubernetesのサービスアカウントにWorkload Identityのユーザーとしてのロールを付与 # それをプロジェクトのサービスアカウントがバインドする gcloud iam service-accounts add-iam-policy-binding \ --role="roles/iam.workloadIdentityUser" \ --member="serviceAccount:sample-project.svc.id.goog[sample-namespace/sample-ksa]" \ sample-project-service-account@sample-project-name.iam.gserviceaccount.com # Kubernetesのサービスアカウントに、プロジェクトのサービスアカウントがどれかをアノテーションする kubectl annotate serviceaccount sample-ksa \ iam.gke.io/gcp-service-account=sample-project-service-account@sample-project-name.iam.gserviceaccount.com
これによりプロジェクトのサービスアカウントが様々なサービスに認証なしでアクセスできるようになります。 アノテーションに間違いがあった場合、--overwriteオプションをつけて再実行することで更新できます。
Cloud SQLコネクタの設定
deployment.yaml
apiVersion: apps/v1
kind: Deployment
# 中略
spec:
serviceAccountName: sample-ksa
containers:
- name: web
# 中略
- name: app
# 中略
env: # appコンテナの環境変数を設定
- name: DB_USERNAME
valueFrom:
secretKeyRef:
name: sample-db-secret
key: username
- name: DB_PASSWORD
valueFrom:
secretKeyRef:
name: sample-db-secret
key: password
- name: DB_DATABASE
valueFrom:
secretKeyRef:
name: sample-db-secret
key: database
- name: cloud-sql-proxy
image: gcr.io/cloud-sql-connectors/cloud-sql-proxy:2.1.0
args:
- "--structured-logs"
- "--port=3306"
- "sample-project-name:zone-name:sample-db-instance"
securityContext:
runAsNonRoot: true
resources:
requests:
memory: "2Gi"
cpu: "1"
volumes:
- name: nginx-sock
emptyDir: {}
KubernetesのSecretに登録した値をappコンテナの環境変数に設定します。Laravelの.envに同名の環境変数があれば、それを上書きします(つまり.env側の記述が不要になります)。 cloud-sql-proxyのargsの3番目に入る値は、Cloud SQLのコンソールの概要 > lこのインスタンスとの接続 > 接続名 から取得できます。
データベースに接続する
gcloud sql connect sample-db-instance --user=sample-db-user
これで直接データベースを操作できます。appコンテナに入ってマイグレーションを実行してから接続すれば、テーブルができています。
終わりに
GCPに関してほぼ無知な状態から、業務で触れる中で多少は理解できてきたと思っていました。しかし、自分で全てをやってみるうちに、氷山の一角でしかないという実感が強くなる一方でした。本当はもっと業務で触れなかったサービスも使ってみようと思っていたのに既知サービスの時点で難航したこと、Workload Identityの件に気づくのが遅すぎて手が回らなかったことなど、悔しい面はたくさんありますが、自分の力量を知る良い機会になりましたし、曲がりなりにもデプロイに漕ぎ着けたことはある程度自信になったと思います。今後もGCPに限らず実践的な学習を続けていき、業務に活かしていきたいです。
参考資料
GitHub Actions を使用してGKEにアプリケーションをデプロイする
PHPの公式DockerイメージでUNIXソケット通信しようとして罠にハマる
新卒1年目を振り返って苦労したことと解決したこと

はじめに
オールアバウトグループの新卒1年目エンジニアが投稿する企画『テックブログ新卒週間2023』。
今回はイシノがお送りします。
私は2022年4月に入社し、6月末まで外部でのエンジニア研修を受けておりました。研修後はメディア開発1Gに所属し業務をしております。
本記事ではメディア開発1Gのメンバーとしてジョインしたのち業務を進めていく中で苦労した点、どうやって改善をしたのかについて紹介していきます。
困っていたこと、どう改善をしたのか
これから社会人一年目の私がぶつかった壁とどうやってそこに向き合って改善をしたのかについて紹介していきたいと思います。
私が困っていたと感じていた点は以下になります。
- 情報量の多さ
- わからない単語、用語の多さ
- All Aboutをはじめとしたメディアを取り扱う運用の方々(以下、「事業部の方」とします)とのコミュニケーションの難しさ
- メディア開発1Gが保持しているアプリケーションの数が多い
- コードが読めない
情報量の多さ
外部での研修を終えた私はこれからどんな開発をしていくのだろうと心を躍らせてチームへとジョインをしました。 その中で一番はじめに感じたことは、情報量の多さです。
私のチームは"メディア"と名前がついていることからメディアAll Aboutをはじめとしたメディアを取り扱う運用の方々とのコミュニケーションをとる機会が多々あります。 そのため、連絡ツール(弊社ではslack)上で目まぐるしいほどの情報が行き来をしています。 何をよく読んだらいいのか、全部認識していないといけないのかと自問自答しながら考えていました。
解決方法として情報の重要度、緊急性を意識するようにしました。 その上で自分の中で、今見るべきなのか今日中に見ればいいのか、と優先順位の位置付けを行うようにしました。 優先度合いががわからない場合には積極的にチーム内でコミュニケーションを取るようにして、話し合うようにしました。
今は業務自体に慣れてきたこともあり、拾える情報の量も増えていますが、それでも一度に多くの情報が入ってくるタイミングはあるのでまとめて見る時間を確保して情報過多になりすぎないような努力を続けています。
わからない単語、用語の多さ
新卒一年目で入社したタイミングから起きていた問題ではありますが、わからない用語がとても多いです。 それも世間一般で使用されているもの、会社固有の用語などもあり初めは会議体での内容もわからないほどでした。
中でもわからない用語が急激に増えたのがチームにジョインしてすぐの1~2週間ほどでした。 開発部内ではインフラ構成周りの用語、他チームのシステムの概要に関する用語、一方メディアの事業部での会議体ではメディアの用語に関してがわかりませんでした。
解決方法として、以下を実施しました。
- メモをとって、わからないところは先輩に質問する
- デジタル単語帳という書籍を用いて学習を行う
会者固有の用語に関しては質問をする以外にはないので時間をいただいて丁寧に回答をしていただけました。
特にメディアに関する用語に関しては、業務中に度々目にする、または利用される場面も多かったため、自分の中で優先度を上げて覚えるように心がけていました。 初めはもちろん一番不明なことが多い時期でもありますが、その中でも少しずつ自分の糧として落とし込んでいくことでチームへのジョインもスムーズになりました。
事業部とのコミュニケーションの難しさ
事業部とのコミュニケーションをとる上で難しいと感じていた点はいくつかあります。
- 技術的な内容をどう噛み砕いて伝えるか
- どうやって認識のずれを起こさないようにするか
1. 技術的な内容をどう噛み砕いて伝えるか
技術的な内容中心に仕様に関してのコミュニケーションを取ろうとするともちろん相手に伝わりません。 事業部の方々はプログラミングに関しての知識はない方がほとんどなので技術的な内容ではなく事実ベースでのコミュニケーションを心がけました。
事実ベースというのは対応を経て何をしたいのか何ができるのかをベースに話をしていくという意味です。 具体的には
- 広告表示がレイアウト調整などのfront側デザイン修正のような対応に関しては画面のモックを作成して目で見える形にする。
- 新たにシステム内に仕様を追加するような対応では例としてボタンをクリックしたらどのような挙動をするのか。
などが明確になる形でのコミュニケーションを行いました。 その結果デザイン修正に関してはデザインが目でみてわかる形になり、より明確に意思疎通が行えるようになりました。 また、仕様など機能追加に関しては事業部の方が想定した挙動ができているのか、使いやすい機能になっているかのフィードバックももらえ、運用の方と開発とで有用的なコミュニケーションをとることもできるようになりました。
2. どうやって認識のずれを起こさないようにするか
簡潔にいうならば綿密にコミュニケーションをとることです。 また、不安のある状態でリリースをしないということを徹底しています。
そのため、少しくどいくらいに仕様に関しては質問を心がけるようにしています。 広告の表示やデザイン修正などに関しては広告が出ているか出ていないか、デザインが修正されているか、されていないかの差しかないのでそこまで認識のずれは起きづらいと思っています。 しかし、特に仕様の追加などに関しては動作検証として実際に動かしてみてもらうというのを行っています。 開発側がこれは使いやすいと思って作成したものが運用側にとってはそこまで使いやすくない、または使いずらいなんてことは往々にあると思います。
- 事業部から提案書をいただく
- それをもとに設計し実装をする
- 運用の方々に触っていただいてフィードバックをいただく
- 再度実装する
このサイクルを行うことがより良いものを開発側と運用側で作るには欠かせないことだと思います。 開発側が使いやすいと思うのはあくまで推測の域を超えないため、綿密なコミュニケーションを心がけて使用を詰めていくことがいいと思います。
メディア開発1Gが保持しているアプリケーションの数が多い
メディア開発Gは他の開発部署に比べて扱うアプリケーションの数がとても多いです。 そのためチームジョイン当初はどのアプリケーションがなんと呼ばれるシステムなのか、理解するだけでも一苦労でした。 アプリケーションがとても多いので配属されて一年経つ今ですら、システム概要に関しての理解が薄いアプリケーションもあります。
この解決方法として私はよく改修の入るアプリケーションを理解するところから始めました。 大きな一つ一つのアプリケーション単位ではなくサービス同士のつながり方を意識して理解することでアプリケーションの点の理解ではなく、線での理解に努めました。 その結果一年たった今ではよく改修の入るアプリケーションに関してはシステム自体の理解、構造の理解に関してある程度の知識をつけることができました。
コードが読めない
恥ずかしながらなのですが、入社した当初はコードから実装を理解することに関してとても苦手でした。 メソッド単体程度ではある程度読解することができていたのですが、全体を通しての処理の流れの理解ができていませんでした。 そのため、チームジョイン当初はメソッドを分割しないで処理の順番で書いてくれたほうが楽なのにくらいに思っていました。
最も今では考え方も変わり1メソッドに1つの役割を意識して実装を心がけています。
こちらに関しては正直慣れていき読めるようになったものもありますが、考え方としてはマクロ的視点を持って読むことだと思います。 プログラミングは入力と出力の繰り返しと入社して間もない頃に先輩からアドバイスをいただきましたが今はそのおかげで素早くコードを読むことができています。 今まではどの行で何が行われているのかを全て把握しようとして情報量の多さに理解ができていませんでしたが、何を引数でもらって何を出力しているのか、これを見るだけで大体の実装は理解することができるのに気づきました。 またショットカットキーなどの理解も増え、実装の内容を追うことに関してはある程度の自信がついてきました。
今後はコードを追うことはできるようになってきたので、そこからのリファクタリングや、改修の際にリーダブルな実装ができるようになりたいと考えております。
終わりに
今回は私がチームにジョインしてから困った点に関してなぜ困ったのか、どうやって解決をしたのかについて紹介させていただきました。
初めはそれこそ時間がかかっていたものの周りの先輩方にアドバイスをいただいて支えていただきながら成長をすることができた1年間だったと思います。
この1年間で学んできたことを後輩に教えていければと思います。 また自身も成長をするために今以上にコミュニケーションをとり、仕事を幅を広げつつ楽しみながらやっていければと思います。